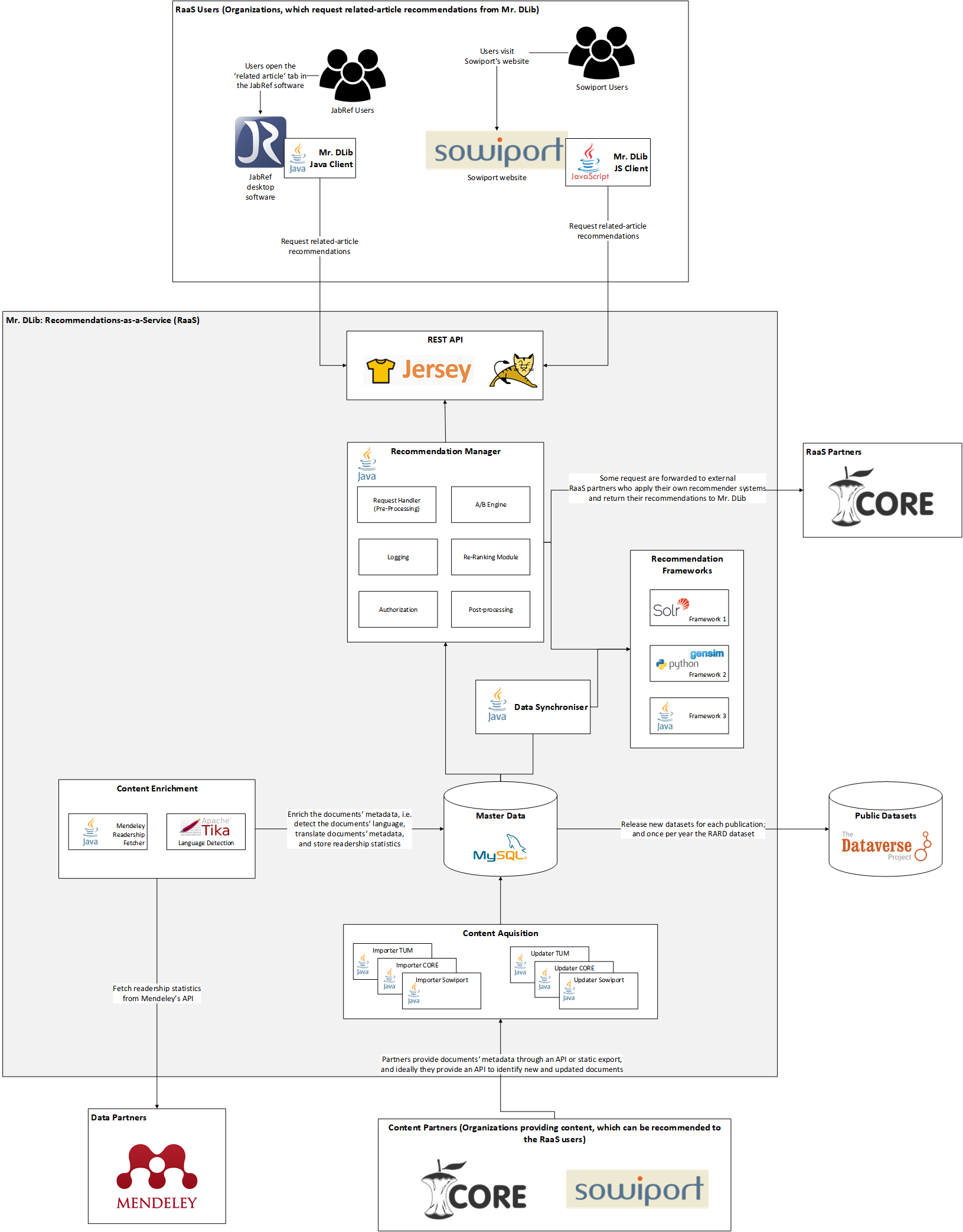
Recommendations as-a-Service (RaaS)
The Architecture of Mr. DLib’s Scientific Recommender-System API
Our manuscript “The Architecture of Mr. DLib’s Scientific Recommender-System API” got accepted at the “26th Irish Conference on Artificial Intelligence and Cognitive Science” (AICS), and here is the pre-print version (HTML below; PDF on arxiv). The bibliographic BibTeX data is: @InProceedings{Beel2018MDLArch, author = {Beel, Joeran and Collins, Andrew and Aizawa, Read more…