This page provides an overview of the projects we operate(d) or are closely affiliated with. We additionally participated in various industrial projects. If you are interested in a collaboration relating to any of our research areas, please contact us.
LensKit-Auto
LensKit-Auto is a flexible automated recommender system (AutoRecSys) toolkit based on LensKit. LensKit-Auto is an open-source tool that performs automated algorithm selection, hyperparameter optimization, and post-hoc model ensembling on all algorithms included in the LensKit Python library.
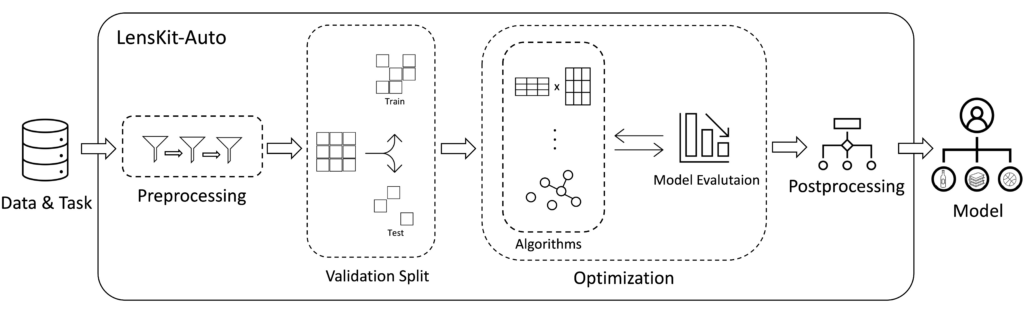
LensKit-Auto is suitable to:
- Warm-start your recommender system development – LensKit-Auto will find and tune the best-performing LensKit algorithm for your dataset.
- Enable you to use recommender systems quickly and easily – LensKit-Auto produces a functioning recommender system with only one line of code.
- Build RecSys pipelines with less engineering effort – LensKit-Auto is a flexible tool that automates labor-intensive engineering tasks required for your design decisions.
LensKit-Auto is the only AutoRecSys tool that automates every step of the recommender system pipeline. When using LensKit-Auto, you do not need to manually select algorithms or hyperparameter configurations. LensKit-Auto always outputs the best-performing model for your dataset, limited only by your time constraints.
GitHub: https://github.com/ISG-Siegen/lenskit-auto
Documentation: https://lenskit-auto.readthedocs.io/en/latest/
Introducing LensKit-Auto, an Experimental Automated Recommender System (AutoRecSys) Toolkit Proceedings Article
In: Proceedings of the 17th ACM Conference on Recommender Systems, pp. 1212-1216, 2023.
InterRed CMS
InterRed was founded in Siegen by Prof. Klahold when he was a PhD student; nowadays Interred is Germany’s largest content management and publishing system, integrating artificial intelligence and machine learning to facilitate multi-channel content delivery. The company’s platform enables businesses to manage, distribute, and personalize content across various digital channels. Central to its offering is the InterRed SmartPaper solution, which automates production processes, allowing for a digital-first workflow that enhances efficiency and scalability.
A key feature of InterRed’s platform is its recommendation and personalization engine. This technology analyzes user behavior and preferences to deliver tailored content experiences, thereby increasing user engagement and satisfaction. By leveraging AI, InterRed’s system can adapt to evolving user needs, providing businesses with the tools to create dynamic and relevant content interactions.
InterRed’s clientele includes prominent organizations such as Axel Springer and Bühler Group. Axel Springer utilizes InterRed’s editorial system for the production of its publications, DIE WELT and WELT am SONNTAG, aiming to automate production processes. Bühler Group has adopted InterRed’s solutions for digital asset management, automation, and AI integration to advance its digital transformation efforts. These collaborations highlight InterRed’s role in supporting large-scale content operations across diverse industries.
Mr. DLib
Mr. DLib is an open-source project to provide recommendations-as-a-service for research articles. Mr. DLib was originally developed as a Machine-readable Digital Library at the University of California, Berkeley, and is nowadays run by researchers, among others, from the University of Siegen (Germany), and the University of Göttingen(Germany).
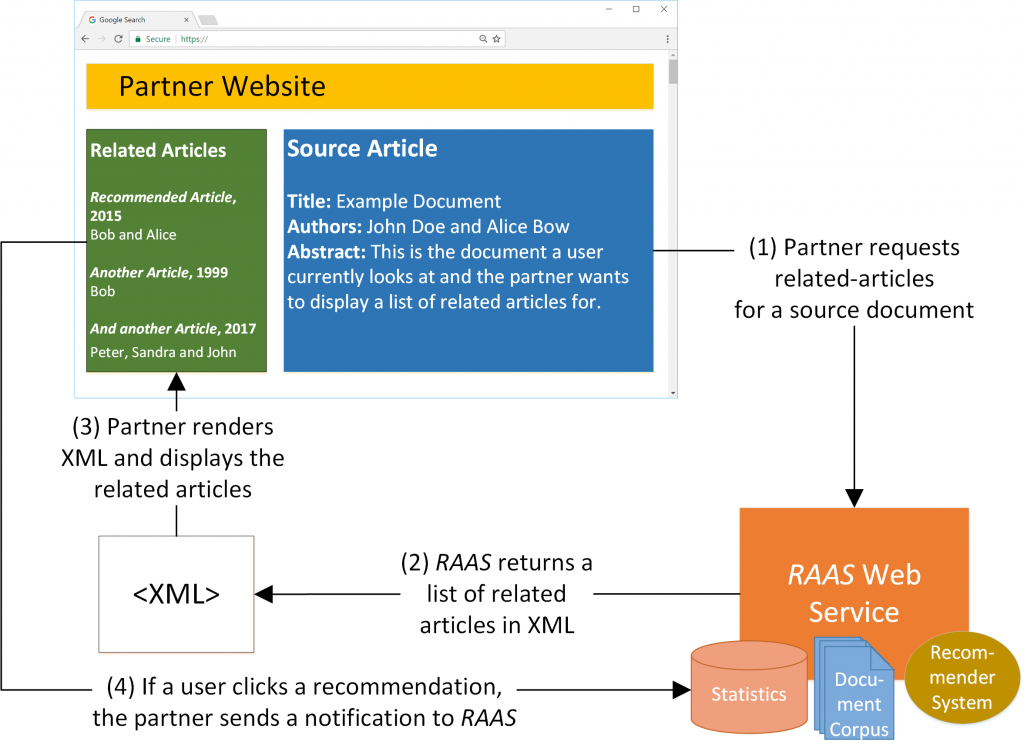
Mr. DLib offers three services:
- Recommendations-as-a-service (RaaS) for operators of academic products
Operators of academic products such as digital libraries or reference management tools can easily integrate a recommender system in their own products with Mr. DLib. To do so, operators need no knowledge about recommender systems. In addition, the effort of integrating Mr. DLib’s recommendations-as-a-service ranges from a few hours to a few days, compared to several months of work for implementing one’s own recommender system. Operators have the choice to recommend only their own content (e.g. research articles) to their users, or content from Mr. DLib’s content providers. - Academic outreach for providers of academic content
Mr. DLib helps content providers such as universities, publishers, conference organizers, and open access repositories to reach out to students and researchers and win them as new visitors, readers, users, or customers. For instance, publishers may gain new readers for their publications; universities may attract new students for their courses; and conference organizers may attract new submissions. Mr. DLib is doing so by recommending the providers’ content — e.g. call for papers, course descriptions, or research articles — to the users of Mr. DLib’s RaaS partners. - A real-world research environment for students and researchers
Mr. DLib shares its data, i.e. we allow external researchers and students to conduct their research with Mr. DLib (as long as the privacy of our partners and users is ensured). In the short-term, we publish datasets that contain the documents indexed by Mr. DLib and information about the delivered recommendations. Our long-term goal is to establish a “living lab” that allows external researchers to evaluate their recommendation algorithm in real-time with Mr. DLib and its partners. Mr. DLib is an ideal environment for research about recommender systems and digital libraries as well as research in the field of machine learning, citation analysis, natural language processing and several related disciplines. So, if you are interested in conducting research that has a real impact on how other researchers work.
RARD II: The 94 Million Related-Article Recommendation Dataset Proceedings Article
In: Proceedings of the 1st Interdisciplinary Workshop on Algorithm Selection and Meta-Learning in Information Retrieval (AMIR), pp. 39–55, CEUR-WS, 2019.
The Architecture of Mr. DLib’s Scientific Recommender-System API Proceedings Article
In: Proceedings of the 26th Irish Conference on Artificial Intelligence and Cognitive Science (AICS), pp. 78–89, CEUR-WS, 2018.
Integration of the Scientific Recommender System Mr. DLib into the Reference Manager JabRef Proceedings Article
In: Proceedings of the 39th European Conference on Information Retrieval (ECIR), pp. 770–774, 2017.
Mr. DLib: Recommendations-as-a-service (RaaS) for Academia Proceedings Article
In: Proceedings of the 17th ACM/IEEE Joint Conference on Digital Libraries, pp. 313–314, IEEE Press, Toronto, Ontario, Canada, 2017, ISBN: 978-1-5386-3861-3.
Introducing Mr. DLib, a Machine-readable Digital Library Proceedings Article
In: Proceedings of the 11th ACM/IEEE Joint Conference on Digital Libraries (JCDL`11), pp. 463–464, ACM, 2011, (Available at http://docear.org).
Docear
Docear is a unique solution to academic literature management, meaning it helps researchers organize, create, and discover academic literature. Among others, Docear offers:
- A single-section user-interface that allows a comprehensive organization of literature (Figure 2). With Docear, users sort documents and annotations into categories (e.g. comments, bookmarks, and highlighted text from PDFs); sort annotations within PDFs; and view multiple annotations of multiple documents, in multiple categories – in parallel.
- A unique ‘literature suite concept’ combines several tools in a single application (pdf management, reference management, and mind mapping). This allows users to draft their papers, assignments, thesis, etc. directly in Docear and copy annotations and references from their collection directly into their draft.
- A recommender system helps researchers discover new literature: Docear recommends papers for which the full-text is freely and instantly available for download, and which are tailored to the user’s information needs.

The Architecture and Datasets of Docear's Research Paper Recommender System Journal Article
In: D-Lib Magazine, vol. 20, no. 11/12, 2014.
The Comparability of Recommender System Evaluations and Characteristics of Docear's Users Proceedings Article
In: Proceedings of the Workshop on Recommender Systems Evaluation: Dimensions and Design (REDD) at the 2014 ACM Conference Series on Recommender Systems (RecSys), pp. 1–6, CEUR-WS, 2014.
Docears PDF Inspector: Title Extraction from PDF files Proceedings Article
In: Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL'13), pp. 443-444, ACM, 2013.
Introducing Docear's Research Paper Recommender System Proceedings Article
In: Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL'13), pp. 459-460, ACM, 2013.
An Exploratory Analysis of Mind Maps Proceedings Article
In: Proceedings of the 11th ACM Symposium on Document Engineering (DocEng'11), pp. 81-84, ACM, 2011, (Available at http://docear.org).
Retrieving Data from Mind Maps to Enhance Search Applications Journal Article
In: Bulletin of IEEE Technical Committee on Digital Libraries, vol. 6, no. 2, 2010, (Available at http://docear.org).
Docear4Word
Docear4Word is an add-on for Microsoft Word (2003 and later) that allows inserting references and bibliographies from BibTeX files to MS-Word documents. You can choose from 1,700+ citation styles (APA, MLA, Turabian, Harvard, IEEE, ACM, …). All you have to do is selecting a reference from your BibTeX database, and Docear4Word is doing the work. Docear4Word works with any BibTeX database, not only the ones from Docear. That means you can use Docear4Word with almost any reference manager (JabRef, Bibdesk, Biblioscape, Bibus, Citavi, …). Docear4Word is free to use, open source (GPL 2 or later) and based on the Citation Style Language (CSL), the same one that Zotero, Mendeley and Papers are using.

Affiliated Projects
The following projects are not primarily developed by us, but we co-initiated them, contributed significantly to them, or know the developers well. Consequently, if you are interested in participating in these projects, or conducting research on them, feel free to contact us.
Project Aiur (by Iris.ai)
I am on the advisory board of the Aiur project, which is led by Iris.ai. The team of Aiur envision a democratized scientific world through the Blockchain where the right scientific knowledge is available at our fingertips; where all research is validated and reproducible; where interdisciplinary connections are the norm; where unbiased scientific information flows freely; where research already paid for with our tax money is freely accessible to all; where massive R&D budgets also benefit contributors to core scientific breakthroughs.

Originstamp
OriginStamp is a trusted timestamping service (web and app) that uses the decentralized Bitcoin blockchain to store anonymous, tamper-proof time stamps for any digital content. OriginStamp allows users to hash files, emails, or plain text, and subsequently store the created hashes in the Bitcoin blockchain as well as retrieve and verify time stamps that have been committed to the blockchain. OriginStamp is free of charge and easy to use and thus allows anyone, e.g., students, researchers, authors, journalists, or artists, to prove that they were the originator of certain information at a given point in time. Common use cases of OriginStamp include proving that:
- a contract has been signed or a task was completed prior to a certain date.
- a photo or video has been recorded prior to a certain date.
- an idea for a patent already existed prior to a certain date, e.g., prior to signing an NDA.
The idea of timestamping is not new. Even before computers existed, information could be encoded and the code could be published, for example, in a newspaper. However, we use the blockchain of the cryptocurrency Bitcoin as a decentralized, tamper-proof, and cost-efficient timestamping authority.
CitePlag
CitePlag is the first plagiarism detection system to implement Citation-based Plagiarism Detection (CbPD) – a novel approach capable of detecting also heavily disguised plagiarism in academic texts. Existing plagiarism detection software only examines literal text similarity, and thus typically fails to detect disguised plagiarism forms, including paraphrases, translations, or idea plagiarism. CbPD addresses this shortcoming by additionally analyzing the citation placement in the full-text of documents to form a language-independent semantic “fingerprint” of document similarity.
CbPD can be applied to any text containing citations – this includes academic documents, scientific publications, patents, legal cases, etc. The approach overcomes the shortcoming of existing text-based plagiarism detection methods. Existing methods typically fail to detect translated and strongly disguised plagiarism instances, since they only examine words (i.e. text overlap) in documents to detect suspicious similarity.
Our observations confirmed that citation pattern similarity often remains detectable even if the text has been translated or strongly paraphrased. Thus, in many instances, CbPD allows detecting plagiarisms that could otherwise not have been automatically identified using the traditional text-based approaches: for example, when text was sufficiently disguised by synonyms or word rearrangement, or because the copied text was translated. That citation patterns in plagiarized texts often have suspicious similarities with the citation patterns in the original source document(s) was also confirmed in our analysis of the plagiarized doctoral thesis of Karl-Theodor zu Guttenberg as well an analysis of the VroniPlag Wiki performed in. An evaluation of the citation-based approach on a large scale collection of over 200,000 scientific publications in the PubMed Central Open Access Subset demonstrated the practicability of the approach in a real-world setting and on a range of realistically disguised plagiarism forms.
Comparative Evaluation of Text- and Citation-based Plagiarism Detection Approaches using GuttenPlag Proceedings Article
In: Proceedings of 11th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL'11), pp. 255–258, ACM, Ottawa, Canada, 2011, (Available at: url http://sciplore.org/pub).
Citation Based Plagiarism Detection - a New Approach to Identify Plagiarized Work Language Independently Proceedings Article
In: Proceedings of the 21st ACM Conference on Hypertext and Hypermedia, pp. 273–274, ACM, Toronto, Ontario, Canada, 2010, (Available at: url http://sciplore.org/pub).
news-please
news-please is an open source, easy-to-use news crawler that extracts structured information from almost any news website. It can follow recursively internal hyperlinks and read RSS feeds to fetch both most recent and also old, archived articles. You only need to provide the root URL of the news website. news-please also features a library mode, which allows developers to use the crawling and extraction functionality within their own program.
The core functionalities include:
- full website crawling (users only need to provide the root URL)
- crawling of recent (using RSS) and old articles (using sitemaps and recursive link analysis)
- information extraction with a precision of 0.7
- runs in two modes: CLI or can be accessed via an API in your own code
JabRef
JabRef is an open source bibliography reference manager. The native file format used by JabRef is BibTeX, the standard LaTeX bibliography format. JabRef is a desktop application and runs on the Java VM (version 8), and works equally well on Windows, Linux, and Mac OS X.
BibTeX is an application and a bibliography file format written by Oren Patashnik and Leslie Lamport for the LaTeX document preparation system. General information can be found on the CTAN BibTeX package information page. JabRef also supports BibLaTeX.
Bibliographies generated by LaTeX and BibTeX from a BibTeX file can be formatted to suit any reference list specifications through the use of different BibTeX and BibLaTeX style files.
RARD II: The 94 Million Related-Article Recommendation Dataset Proceedings Article
In: Proceedings of the 1st Interdisciplinary Workshop on Algorithm Selection and Meta-Learning in Information Retrieval (AMIR), pp. 39–55, CEUR-WS, 2019.
The Architecture of Mr. DLib’s Scientific Recommender-System API Proceedings Article
In: Proceedings of the 26th Irish Conference on Artificial Intelligence and Cognitive Science (AICS), pp. 78–89, CEUR-WS, 2018.
Integration of the Scientific Recommender System Mr. DLib into the Reference Manager JabRef Proceedings Article
In: Proceedings of the 39th European Conference on Information Retrieval (ECIR), pp. 770–774, 2017.
Past Projects
The following projects are not actively developed anymore. However, if you are interested in continuing to develop one of the projects, or using it as the foundation for your own work, feel free to contact us.
DISCANT
Domain-Independent Semantic Annotation of the Text (DISCANT): Surrounded by huge and exponentially growing volume of information of various nature, every day we face challenges with keeping track of the latest news in a domain of interest or finding good-quality answers to specific questions. The problem of information overload has been addressed by modern information systems and search engines, however, their capabilities are strongly limited by using unstructured textual formats for exchanging and storing information. Textual documents often contain a lot of concrete facts and quantifiable information, but the communication of these facts and information through human languages renders them inaccessible to machines. This “semantic bottleneck” problem substantially slows down communication and knowledge propagation in the world. In order to equip machines with the ability of effective processing of the text, DISCANT (“Domain-Independent SemantiC ANnotation of the Text”) aims at creating a comprehensive framework for semantic annotation of textual documents of arbitrary domains, such as scientific papers, legal documents, customer reviews or clinical trial reports. We will develop approaches, methods and tools for two classes of solutions: an environment for discovering entity and relation types in a given domain and a system for automated semantic annotation of the text. The project proposes a novel approach based on a combination of unsupervised natural language processing and machine learning techniques. DISCANT will advance machine understanding of the text, contributing to the release of important knowledge buried in textual documents, the creation of machine-readable knowledge repositories and more effective solutions for semantic search and personal recommendations. As a consequence, DISCANT will equip the consumers of textual documents with better tools for overcoming data deluge and information overload, enabling them to make better-quality, data-driven decisions.
Cermine
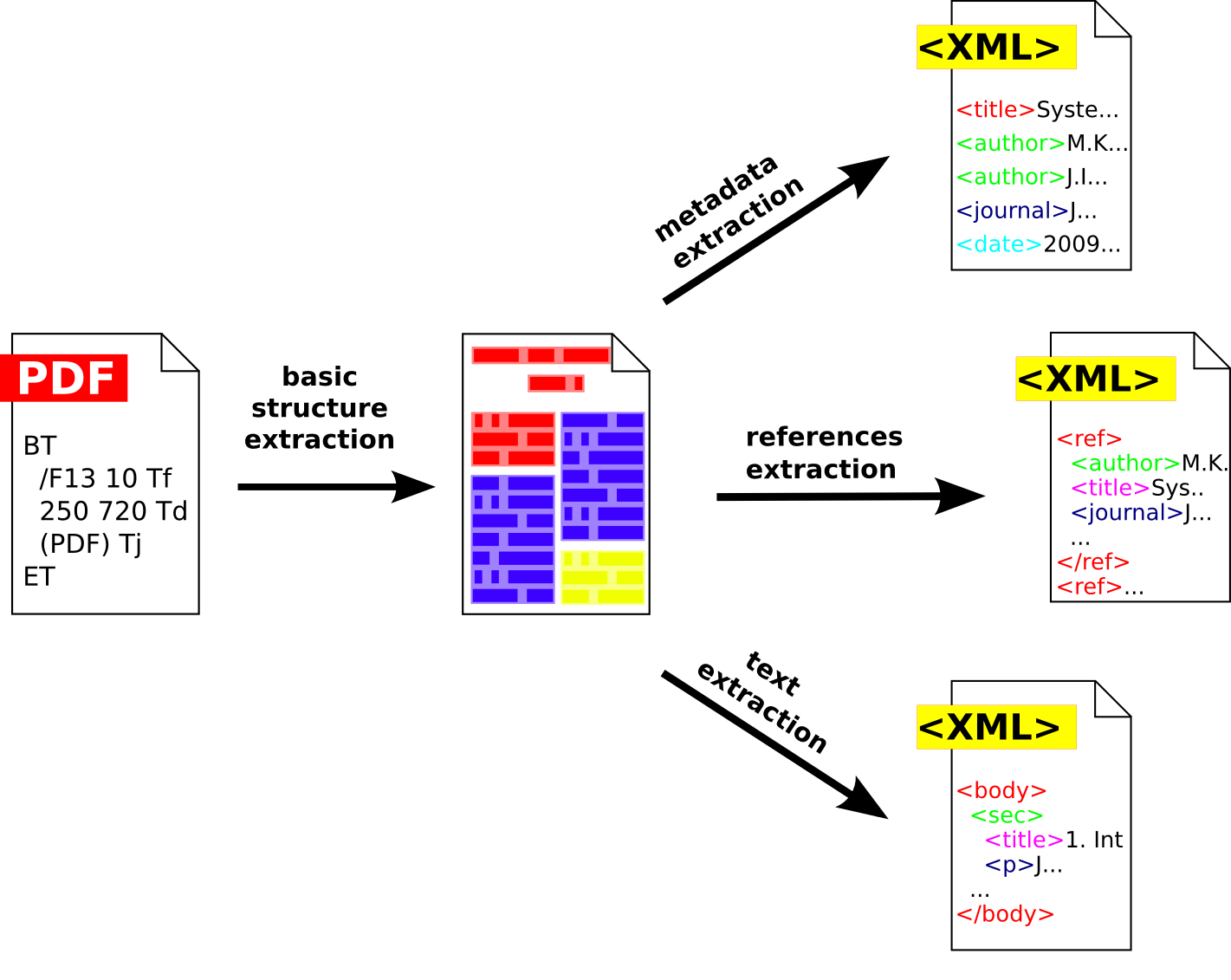
CERMINE is a comprehensive open source system for extracting metadata and content from scientific articles in born-digital form. The system is able to process documents in PDF format and extracts:
- document’s metadata, including title, authors, affiliations, abstract, keywords, journal name, volume and issue,
- parsed bibliographic references
- the structure of document’s sections, section titles and paragraphs.
CERMINE is based on a modular workflow, whose architecture ensures that individual workflow steps can be maintained separately. As a result, it is easy to perform evaluation, training, improve or replace one step implementation without changing other parts of the workflow. Most steps implementations utilize supervised and unsupervised machine-leaning techniques, which increases the maintainability of the system, as well as its ability to adapt to new document layouts.
CERMINE uses supervised and unsupervised machine-leaning techniques, such as Support Vector Machines, K-means clustering and Conditional Random Fields. Content classifiers are trained on GROTOAP2 dataset. More information about CERMINE can be found in this presentation.
CERMINE contains a REST service that allows for executing the extraction process by machines. REST service can be useful for digital libraries that do not have access to a built-in method for extracting metadata and content from documents. It can be accessed using cURL tool:
$ curl -X POST --data-binary @article.pdf \ --header "Content-Type: application/binary" -v \ http://cermine.ceon.pl/extract.do
PDF Inspector
PDF Inspector is a JAVA library that extracts titles from a PDF file — not from the metadata but from its full-text. More precisely, PDF Inspector extracts the full-text of the first page of a PDF file and looks for the largest text in the upper third of that page. This text is returned as the title. Of course, this does not always deliver the correct title (sometimes, for instance, the journal name is formatted in a larger font size than an article’s title) but in about 70% you will get the correct title. Based on our tests, this accuracy is equally effective as more complex machine learning algorithms, but much faster. The main features of PDF Inspector are
- Extracts titles from PDF files with good accuracy (~70%) and excellent run-time (few milliseconds per PDF in batch mode)
- Usable as JAVA library (other tools such as reference managers can easily integrate PDF Extractor to extract titles from PDFs.
- Usable as stand-alone command-line application (returns a PDFs’ title on the command line)
- Usable in batch mode (stores the extracted titles into a CSV file)
- Reads all PDF versions (other tools such as SciPlore Xtract or ParsCit are using PDFBox for processing the PDFs. However, PDFBox sometimes has problems extracting text from PDFs not being 100% compliant to the PDF standard – PDF Inspector is based on jPod, which is more tolerant)
- Written entirely in JAVA 1.6. Hence, PDF Inspector runs on any major operating system, including Windows, Linux, and Mac OS, without any other tools required (besides the JAVA run time environment, of course)
- Completely independent of further tools – you only need PDF Inspector, that’s it
- Released under the GNU General Public License (GPL) 2 or later, which means it is free to use and its source code can be downloaded and modified.
Beel, Joeran, Stefan Langer, Marcel Genzmehr, and Christoph Müller. “Docears PDF Inspector: Title Extraction from PDF files.” In Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL’13), 443–444. ACM, 2013.
DragBase
Dragbase is a library, written in C, which adds enhanced drag-and-drop functionality to your Windows software – independently of the programming language your software is written in. It takes a few minutes to integrate Dragbase into your software. With dragbase, users can drag-and-drop the currently opened file to any other application. For instance, the file, respectively the icon, could be dropped in the Windows Explorer to a certain directory and the file would be saved in this directory. Or the file could be dropped in Microsoft Outlook and then a new email would be created with the file as an attachment. Watch the video for more details.
AccessAngel
AccessAngel is a software that enables your computer to automatically lock itself when you leave your workspace ensuring that no unauthorized access is made to your data. The software achieves this by monitoring the Bluetooth connection between your cell phone and your computer. If the signal gets weak, e.g. when leaving the room, the computer locks itself automatically and unlocks itself upon returning.

The GSM-Guardian Angel
Every year, car accidents kill approximately 7,000 people – in Germany alone. Research from the University of Würzburg shows that over 700 lives could have been saved annually if emergency medical services had been notified immediately after the accidents occurred. Currently, minutes and in some cases even hours pass before the accident is discovered and an ambulance called – valuable time in which emergency services could have already arrived or initiated treatment. The question arises, why are emergency services not automatically notified using what already exists? That is, the cellular network and a cell phone, which knows the position.
We have developed a flexible and cost-effective emergency calling system – the “GSM Schutzengel” or “GSM guardian angel”, which we originally presented in the context of Jugend-forscht, a research competition for young scientists. Our solution lies in what looks like an ordinary cell phone battery, but additionally contains an acceleration sensor and a microcontroller to evaluate the data gathered. With this add-on, it is possible to upgrade any standard cell phone into a mobile ‘guardian angel’, which reliably recognizes high-impact accidents. False alarms are not caused if the driver abruptly brakes or the phone falls down. When a car accident has occurred, the GSM guardian angel immediately contacts the emergency medical services. Thus, even unconscious drivers can immediately receive help. The position of the accident is determined using the mobile network – accurate to 150 meters, so assistance can be called directly to the scene of the accident.
By determining the position of an accident using GSM technology the system is flexible and inexpensive. Thus, the system fulfills the criteria necessary for an area-wide emergency calling system to be feasible in practice – this so far is unique! No other emergency calling system on the market offers all the advantages of the GSM guardian angel.
We continued the research project after the Jugend Forscht competition, and sold the product in 2004. The idea has since been adopted, as eCall in Europe and as GM’s OnStar service in North America.
Mobile GPS Locator
In 2001, GPS receivers were slowly becoming smaller, and it seemed likely they would soon be integrated into mobile phones. At the time, they were still around the size of the mobile phone itself! However, in anticipation, we developed ‘Mobile GPS Locator’ – a software to geo-locate mobile devices or PDAs from other mobile devices or from a desktop PC. The system allows pinpointing the location of your friends, co-workers, or any product running the software by simply using your cell phone. Use of the system only requires a cell phone with a compatible GPS receiver and support for Java’s J2ME (Java 2 Micro Edition). Infineon Technologies AG demonstrated the software at the 2002 CeBIT to give an outlook on the future of mobile developments.

Probability Abstract Service
The Probability Abstract Service (PAS) is a free and open digital archive of research article abstracts in the field of mathematical Probability. From 2010 to 2015 the service was provided as a joint effort of Prof. Jim Pitman from the University of California, Berkeley and our group.
The PAS offers comprehensive, integrated information about articles and authors in the probability community. All data in the PAS is easily accessible through a web-interface and openly available for download in JSON and XML format. The PAS updates itself daily by retrieving new articles from the Open Access preprint collection arXiv. arXiv is widely adopted by the probability community for offering pre-print full-text articles. The PAS, which predates arXiv, continues to be a valuable service, offering a sharper focus, more convenient and condensed display and browsing options, and disambiguation of authors.
The PAS was started in 1991 by Rich Bass (Univ. of Connecticut) Krzysztof Burdzy (Univ. of Washington) and Mike Sharpe (UC San Diego), who initiated the service as an email newsletter that informed interested readers about new articles in the field. The service gradually evolved from a newsletter to a web-interface offering browsing and search capabilities. Until October 2004, Krzysztof Burdzy and Larry Susanka (Bellevue College, Washington) maintained the service before transferring it to Stefano M. Iacus (Univ. of Milan, Italy), who hosted it until 2010. In 2010, Prof. Jim Pitman took over responsibility for the PAS and hosted the service in cooperation with our group at the University of California, Berkeley until January 2015.
In cooperation with Prof. Pitman and partially supported by a NSF grant, members of the AGIS group extended the PAS for machine-readability by developing a new data backend. Since this renewal, Mr.DLib, an acronym for Machine‑readable Digital Library, handles all data-related tasks. Mr.DLib manages the import and disambiguation of records from arXiv, their storage and maintenance, and provision of JSON and XML exports of data in form of a RESTful web service. Our improvements to the web-interface comprise the addition of an author index, which allows displaying all articles of specific authors, among other usability enhancements.
0 Comments