This page provides guidelines on academic writing for students. We are very open to comments and feedback.
This page is outdated. The most up-to-date version can be found here: https://recommender-systems.com/best-practice/academic-writing/
First Rule: Think!
These guidelines are not the Bible: there might be situations in which breaking the rules is advantageous; some tips might be based on wrong assumptions, or they might be just not appropriate for your work style. Therefore: Challenge the rules and discuss them with your co-workers and supervisor(s).
Structure of a paper or thesis
When writing a paper or thesis, please stick to the following structure. There is very rarely a good reason to not doing so. If you believe there is, please discuss with your supervisor first.
Title
A good title is catchy yet descriptive, and it makes clear that you have created something awesome.
The standard title many students choose is Doing X Using Y. For instance
- Detecting Cancer in Images Using Machine Learning
- Using kNN for News Recommendations
That’s extremely boring. More importantly, just applying (or “using”) some out-of-the-box machine learning algorithm to solve a well know problem, is one of the less good things you can do in academia. Ideally, you create something completely new. Therefore, even if you have just applied e.g. an out-of-the-box algorithm (which may be fine for a Bachelor or Master thesis), you don’t want to point your readers to it directly in the title.
Consider the following
- Give your algorithm or method a name
- Avoid the term “using”
- Make the title special
For instance, instead of writing “Using kNN for News Recommendations” maybe better “kNNews: A novel Technique for News Recommendations”
Abstract
Most people don’t put much effort into writing their abstracts – that is a mistake! The abstract is the text that makes a reader decide whether to read your paper or not. Many readers might even only read your abstract to decide whether to cite your paper (or what information to cite). I claim that with a good abstract you can double or triple the probability that someone reads and/or cites your paper. So, think about it: You have spent weeks or months to do your research and to write the paper. Hence, you should not only spend 2 minutes writing your abstract. Personally, I assume that 70% of the researchers who cited my work, have only read the abstract of my papers.
When writing an abstract do the following
- Be specific: Provide numbers, in particular, give the most important numbers from your results.
- Bad: “We compared method A and B and present the results in our paper” (without saying which method was better, and what the actual results are)
- Mediocre: “We compared method A and B and found that A is more effective than B”
- Best: “We compared method A and B in an online evaluation with 8 million recommendations delivered to 300 thousand users. We found that A is 35% more effective than B with a precision of 0.76 vs. 0.56 (p<0.01)”
- Focus on your results. Many people write ten sentences about e.g. how important recommender systems are and then one sentence about their main finding. It should be the opposite. Potential readers most likely know already what e.g. recommender system ist. So, don’t waste too much word on providing background information in the abstract. Describe as many results and findings as possible.
- Write a lot: The abstract is the text that is publicly available and that is indexed by search engines etc. So, write a decent amount of words. In particular, if there is no page limit, writing a few hundred words is fine (if you have enough relevant information to put in).
A very nice example of a good abstract is this:

The abstract has around 1 sentence for each important part, i.e. each key chapter in the paper (introduction/background; problem; goal; methodology; results) and the benefit is very clear (found the wreckage within 1 week, while others were unsuccessful for 2 years).
Introduction
The introduction provides some background information, outlines the research problem and states the research question and goal. In a normal 8-page research paper, the introduction is around 1 page and all information (background, research problem…) is provided without sub-headings. In a long document such as a dissertation, you may have separate sections.
Background
Every academic document starts with a brief (!) background that helps your readers to understand the context of your work. It also helps readers who are not perfectly familiar with your field of research and informs them of the most important concepts and methods (so they know at least the names and can look it up if they want). For instance
Recommender-system evaluation is an actively discussed topic in the recommender-system community. Discussions include advantages and disadvantages of evaluation methods such as online evaluations, offline evaluations, and user studies; the ideal metrics to measure recommendation effectiveness; and ensuring reproducibility. Over the last years, several workshops about recommender-system evaluation were held and journals published several special issues. <<– This paragraph povides background information about recommender-system evaluation in general. It could be removed if space was needed
Typically, researchers calculate a few metrics for each algorithm (e.g. precision p, normalized discounted cumulative gain nDCG, root mean square error RMSE, mean absolute error MAE, coverage c, or serendipity s). For each metric, they present a single number such as p = 0.38, MAE = 1.02, or c = 97%, i.e. the metrics are calculated based on all data available. <<– This second paragraph provides more specific background information on how to evaluate recommender systems.
Every researcher in the field of recommender systems knows these things. However, these two paragraphs are for readers who maybe don’t know so much about recommender system evaluation. It also makes clear what your basic assumption is, namely that there is lots of discussion about recommender-system evaluation, and what the standard metrics are. In a research paper, the background should not be longer than one or two paragraphs. In a dissertation, no more than one or two pages. In case of a dissertation, you can provide more background information in a separate section (see below).
Research Problem
Once you introduced the reader to the topic via the background section, you present the problem that currently exists. Every research paper and thesis must clearly state a research problem. If you send us a draft, we want to see one sentence like this:
- “The problem is… “
- “Problematic with this practice is that…”
- “The disadvantage is…”
A research problem motivates your research, and formulating a convincing research problem is crucial. If readers/reviewers do not understand the problem, they will consider your work as insignificant, and ignore/reject it.
A research problem must be as specific and measureable as possible. Ideally, you can specify the problem in terms of error, cost, time, or lives.
Bad: Researchers struggle to find relevant research papers <— what does “struggle” mean?
Soso: Researchers spend a lot of time to search for relevant work, and yet they often miss some relevant work.
Good: Researchers spend an average of 30 hours per month to search for relevant work [3], and yet it is estimated that researchers miss 24% of relevant work [8, 12]. <<— a very specific measurable problem.
If you are so specific, you will also be able to specify the benefit of your work much better once it is completed.
Bad: Our recommender system helps researchers to better find relevant work.
Good: Our recommender system saves researchers on average 12.4 hours per month, and provides them with 13.9% more relevant work.
The research problem is presented after your background paragraph. For instance:
Typically, researchers calculate a few metrics for each algorithm (e.g. precision p, normalized discounted cumulative gain nDCG, root mean square error RMSE, mean absolute error MAE, coverage c, or serendipity s). For each metric, they present a single number such as p = 0.38, MAE = 1.02, or c = 97%, i.e. the metrics are calculated based on all data available. <– Background
An issue that has not been addressed by the community, is the question for which intervals metrics should be calculated, and how to present them. Currently, metrics express how well an algorithm performed on average over the period of data collection, which may be quite long. For instance, the data in the MovieLens 20m dataset was collected over ten years [15]. This means, when a researcher reports that an algorithm has e.g. an RMSE of 0.82 on the MovieLens dataset, the algorithm had that RMSE on average over ten years. We argue that presenting a single number (i.e the overall average) is problematic as an average provides only a broad and static view of the data. If someone was asked how an algorithm had performed over time – i.e. before, during, and after the data collection period, the best guess, based on a single number, would be that the algorithm had the same effectiveness all the time.
It is not easy to find the right research problem, because a problem can be very high, or very low-level. For instance:
- The world is not advancing as good as it could because…
- Researchers work not as effectively as they could because…
- Researchers face the problem of information overload because …
- Every year so many new research articles are published and because …
- The techniques to deal with information overload (i.e. recommender systems) are not yet effective because…
- It remains unknown, which recommendation approaches are most effective because…
- Most research about recommender systems is not reproducible because …
- …
Each of the points is a valid research problem, and you could theoretically pick any of them. Which one eventually to choose depends on your audience and, of course, what you eventually plan to do.
Research Question
A research question derives from the research problem. For instance:
Research Problem: Most research about recommender systems is not reproducible
Research Question: How to improve reproducibility for recommender-systems research?
If you send us a draft, we want to see a sentence like
In my work, I am tackling the following research question: …
Research Goal / Objective / Hypothesis / Benefits
There is no clear distinction between a research goal and a research objective. Generally, a goal tends to be more vague, visionary and long-term oriented than a research objective. For instance,
Research Goal: “Our goal is to reduce information overload for scientists
Research Objective: Our research objective is to develop recommendation approach that takes users’ demographics into account.
Or something like
Our goal is to identify how performance assessments of recommendation algorithms differ when time-series are used instead of single-numbers.
A hypothesis is similar and just a different way of expressing. For instance
We hypothesize that, instead of a single number, recommender-systems research would benefit from presentingtime series metrics, i.e. each metric should be calculated for a certain interval of the data collection period, e.g. for every day, week, or month. This will allow to gain more information about an algorithm’s effectiveness over time, identify trends, […]
It is important to note the difference between a goal and a task or methodology. A goal would be to e.g. generate new knowledge or reduce a problem. The following are not goals:
Wrong: Our ‘goal’ is to evaluate Algorithm A and B
Wrong: Our goal is to conduct a survey
Doing an evaluation or conducting a survey is not a research goal. An evaluation is only part of the methodology to achieve a goal.
The goal would be e.g. as follows:
Our goal is to identify which of the two algorithms A and B is more effective (and to achieve this goal, we do an evaluation).
Similarly,
Wrong: Our goal is to improve recommender systems with machine learning
Using machine learning is not a goal, it is only the means to achieve the goal (improving recommender systems).
Also, please explain what the potential benefit/contribution will be through achieving your goal. Will your work eventually save lives? Or reduce costs? Generate more profit? Save time?
Research Tasks
In a normal paper, you do not need to state explicitly the research tasks. Only if you are pursuing a really big project (such as a PhD) you might want to break down your research objective into some tasks and describe them in a separate section.
Contribution
It is crucial that you explicitly state the contribution(s) that you made and the resulting benefit, ideally in a quantified way. You can do this in the introduction, as a separate section, and/or in the conclusion or summary.
The best contributions are:
- Make humans live longer
- Make humans happier
- Save money or time (or increase profit)
In computer science, good contributions are
- A new algorithm, process or software that is cheaper/faster/better than the state-of-the-art
- A new dataset, method or tool that enables others (e.g. other researchers) do to better work
- Best-practice guidelines
- New knowledge
Direct benefits that result from your contribution may be
- Faster training of machine learning algorithms
- Higher effectiveness of algorithms
- Lower energy consumption of servers
- More effective and efficient work of users
- …
Ideally, you can quantify your contribution. For instance:
Our contribution is a novel recommendation algorithm that increases the effectiveness of literature recommendations by 16% over the state of the art, and hence helps to cope better with information overload.
Our contribution is the release of a public dataset, which is the first dataset in the domain of research paper recommender systems. It enables researchers to conduct more realistic research about literature recommender systems.
Don’t confuse a contribution and a task. For instance “We conducted an extensive study with 300,000 users” is no contribution, it is a task to validate your contribution.
Also, if you are the first to do something, then say so explicitly.
“To the best of our knowledge, we are first to do/use/show …”
Background
For a dissertation, it may be necessary to provide additional background information. This background section may contain text-book style information about the broader topic. For instance, an explanation of what machine learning is, how neural networks work, how standard evaluation metrics are calculated, etc. When deciding what information to put in the background section, ask yourself:
- Does an expert in your field know these things already?
- Is similar information already available on Wikipedia or in a textbook?
If yes, then the information should be in the background section. Also, don’t confuse this separate background section with the brief background section in the introduction. The background section in the introduction should be very brief. The separate background section can be long. However, do not spend too much time with this section, as you usually do not get credit for it. Instead, rather point readers to available work (e.g. textbooks).
Related Work
When writing a related-work section, keep the following guidelines in mind.
Only provide information relevant to the research problem
The related work section summarizes what others have done to accomplish the same research objective that you are trying to accomplish. It is not a text-book style introduction to your research topic! For instance, if you develop a novel algorithm for a recommender system in digital libraries, then the related work section should cover other novel algorithms for recommender systems in digital libraries. This means you should describe what other researchers’ attempts were to solve your research problem. Explain why their attempts were not yet successful and what must be done better. The related work section should not explain what recommender systems and digital libraries are and how they work! Such information is not necessary because your audience should know all this already. If you feel such information is necessary, place it in the appendix or a separate background section.
Create New Quantifiable (Meta) Information
A good literature survey, i.e. related work section, a) demonstrates your thorough understanding of the topic and b) provides new knowledge. It does not only summarizes paper by paper. Instead, you critically analyze existing work and provide novel meta information.
Bad
Giles et al. (1999) use collaborative filtering for their recommender system, and use citations as implicit ratings ratings. Beel et al. (2013) use content-based filtering for their recommender system, and use the terms from the documents titles. Jon & Doe (2008) also use content-based filtering, and use the terms from the documents abstracts. <– In this example, one paper after the other is described. No critical thinking is demonstrated and no new information is provided.
Good
Only in the early times of recommender systems, i.e. in the 1990’s, some authors used collaborative filtering based on citations (e.g. Giles et al. 1999; …). Nowdays, 53% of the reviewed recommender systems use content-based filtering (e.g. Beel et al. 2013; Jon & Doe, 2001) and extract the terms either from the title (Beel et al., 2013) or abstract (Jon & Doe, 2008). However, the results of many studies need to be looked at with care. 72% of the studies were conducted with less than 15 users, and did not provide statistically significant results.
Have a look at one of our literature surveys for a good example of how to summarize and analyse related work.
Be critical (but fair)
Explain what the shortcomings of the current works are, without letting someone else look stupid. Avoid judgmental words like “bad”, “poor”, “wrong”.
Bad
John Doe (2005) conducted a poor user study with only 15 participants. Hence, the results are meaningless.
Good
John Doe (2005) conducted a
pooruser study withonly15 particpants.Hence, the results are meaningless.While the results are interesting, they are statistically not significant.
Searching For Related Work
Follow the “onion” principle. This means you search first for work that is as closely related to your goal as possible. For instance, when you want to develop a content-based-filtering recommender system for digital libraries, then you search for literature about content-based filtering recommender systems for digital libraries. If you do not find (enough) related work then you broaden your search. For instance, you look into “collaborative-filtering based recommender systems for digital libraries”. If you don’t find a lot of work on that, then you search e.g. separately for “recommender systems” and “digital libraries”, or disciplines such as “content-based filtering for recommender systems in academic search engines”.
Methodology
Describe how you will achieve the research objective. Describe the study design, metrics, datasets, libraries being used etc.
Results
A results section may be split into “implementation” — if you did a comprehensive implementation — and “evaluation” . Otherwise, just presents the results of your evaluation.
Describe your results objectively, i.e. only the numbers. No reader who reads this section should be saying “I disagree”. For instance, you can write things like “algorithm A had a precision of 0.73 and algorithm B had a precision of 0.63” without a deeper interpretation.
Discussion/Interpretation
In this section, you interpret and discuss your results. For instance “given the precision, algorithm A seems to be more effective than B. However, …”.
For smaller projects (e.g. a research paper), you can combine the discussion and result section.
Conclusion
Here you answer the “so what?”. What do your results really mean? What are your conclusions? Have you achieved your research goal? For instance, “We propose that, given our findings, recommender systems should use algorithm A instead of B”. Again, for rather short manuscripts (research papers), you may merge results, discussion and conclusion.
Summary
In most documents (6+ pages) you should have a summary. The summary should summarize the most important information from each previous section.
Future Work and Limitations
Describe what the limitations of your research are (e.g. “we only used documents from the medical domain, hence our conclusions should not be generalized to other domains”), and what else you might want to do (e.g. “As next steps, we plan to repeat the research with documents from the social sciences. In addition, we want to extend algorithm A with X to see if this further increases precisions”). This section is important. You can demonstrate critical thinking and self-reflection.
Acknowledgements
If you or a co-author has received funding e.g. from DFG, DAAD, or SFI, this usually needs to be acknowledged in the publication. If an ADAPT member (e.g. Joeran Beel) is a co-author of your publication, or if you are (co-) sponsored by ADAPT, you need to mention the following either in a footnote or in the acknowledgements.
This publication emanated from research conducted with the financial support of Science Foundation Ireland (SFI) under Grant Number 13/RC/2106.
References
Short papers and posters typically have between 4 and 8 references
Conference articles typically have between 5 and 15 references.
Journal articles typically have between 15 and 50 references.
Theses (Bachelor, Master, PhD) have typically much more references.
To create references, use a reference management software. Do not manually create reference lists.
General Writing Advise
Focus on your audience (not yourself)
Many people focus on their writing on themselves and what they know and like. However, you are not writing for yourself. You are 1. writing for the reviewers of your manuscript and 2. for other researchers in your field. More precisely, you want to convince these people that you worked on an important problem, and found a good solution. Therefore, as a first step, think about who your reviewers (and readers) might be, and what they might know already, and what they are interested in to read.
For instance, imagine you want to submit a paper about Mr. DLib’s recommender system in digital libraries. For yourself, the best thing about Mr. DLib may be that you can collect so much data and that other researchers might do their research so easily with Mr. DLib. If you submit the paper to a conference about open data, this focus might be fine. However, if you submit the paper to a conference on digital libraries, you might want to emphasize how Mr. DLib can help digital libraries to attract more users. If you submit to a recommender-systems conference, you may want to focus on how technologically sophisticated the recommendation algorithms are.
Similarly, if you write a final year project, your second supervisor will be someone who has probably little knowledge about the field of your research. Hence, you might need to provide more background knowledge as if you were writing for other experts in your field.
Another example, not related to academic writing, but writing in general: I received this email from a researcher who wanted to work under my supervision at Trinity College Dublin. The email concludes with the sentence “I am certain that with your guidance my research capabilities will be highly improved”.

Example in which the audience is not properly identified and addressed
While I am sure that the researcher’s learning experience was the true motivation for the researcher to write me, the learning experience is not my primary motivation for supervising postdocs. My primary motivation to supervise postdocs is that they write research grants, supervise PhD students and, most importantly, publish papers. As such, a much stronger sentence would have been
I am certain that with my knowledge and expertise, I would be a valuable addition to your lab, and I would greatly contribute to the research output of your lab.
Minimize reading and thinking effort (and not the writing effort)
Do not let the reader speculate or guess about anything, especially not about your conclusions. If you do, there will be readers who do not understand or misunderstand you.
This means, first, you need to explain exactly what e.g. figures show:
Bad: Figure 3 shows that recommendation approach A outperforms approach B.
Good: Figure 3 shows that recommendation approach A achieved a CTR of 3.91% and hence outperforms approach B with a CTR of 3.15%.
Second, you must explain the “so what?”
Bad: Recommendation approach A achieved a CTR of 3.91% and hence outperforms approach B with a CTR of 3.15%.
Good: Recommendation approach A achieved a CTR of 3.91% and hence outperforms approach B with a CTR of 3.15%. This means, our novel recommendation approach (algorithm A) outperforms the state-of-the-art (algorithm B) by 26%.
Parallel Structure
To ease the reading, you should use a “parallel structure”. This means, within a sentence (and paragraph) you follow the same structure.
Example 1: Do not mix forms
Not Parallel:
Mary likes hiking, swimming, and to ride a bicycle.
Parallel:
Mary likes hiking, swimming, and riding a bicycle.
Example 2: Clauses
Not Parallel:
The coach told the players that they should get a lot of sleep, that they should not eat too much, and to do some warm-up exercises before the game.
Parallel:
The coach told the players that they should get a lot of sleep, that they should not eat too much, and that they should do some warm-up exercises before the game.
For more details, read here https://owl.english.purdue.edu/owl/resource/623/01/
A good paragraph
One paragraph = One topic
Do not write about different topics in one paragraph. Instead, have one paragraph per topic.
Bad:
Citation-proximity analysis suffers from the same problems as other citation-based approaches for calculating document relatedness. This problem relates to the necessity that documents must be cited before document relatedness can be calculated. However, the majority of research papers is not cited at all [3]. In this paper, we propose a novel citation approach to calculate document similarity. This approach does not suffer from the aforementioned problems…
Good:
Citation-proximity analysis suffers from the same problems as other citation-based approaches for calculating document relatedness. This problem relates to the necessity that documents must be cited before document relatedness can be calculated. However, the majority of research papers is not cited at all [3].
In this paper, we propose a novel citation approach to calculate document similarity. This approach does not suffer from the aforementioned problems…
First Sentence: Mention the topic
The first sentence must mention the main topic the paragraph is about. This way, readers can decide if they want to read the paragraph or skip it and continue with the next one. In addition, mentioning the main topic in the first sentence, allows readers to read only the first sentence of each paragraph and get a good idea what the manuscript is about.
SEXI scheme (State; EXplain; Illustrate/Examples)
The SEXI scheme is typically used for debates to convince the audience of something. The scheme does a very good job for writing, too, because eventually, you need to convince the reader and reviewers that your results are correct and important. The concept of SEXI is as follows.
- State: State your hypothesis/demand clearly (“We must lower income tax to increase the overall tax income for the government”) ← you don’t have to agree with this, it’s just for the purpose of illustration ;-).
- EXplain: Explain the mechanism, i.e. why you believe in the hypothesis: “With a lower income tax rate, people will have more money to spend, hence buy more products, hence businesses will make more revenue, hire more people and eventually create a higher absolute tax income for the state”.
- Illustrate: Provide an example and evidence: “Just imagine, what you would do if you could keep 10% more of your salary? Wouldn’t you be more likely to buy a new car? Or go more often to a restaurant?” OR “A recent study in country X showed that after decreasing taxes for individuals, the overall tax revenue increased [4]”)
When writing an academic paper, you need to be more formal, but the general idea is the same.
- You start a paragraph with a statement that makes clear what this paragraph will be about. For instance,
Citation-proximity analysis suffers from the same problems as other citation-based approaches for calculating document relatedness. ← This is your opening statement. However, it is just a claim. People may or may not believe it.
- Once you made your statement, you need to explain the statement, in case that someone did not understand what you mean. And yes, that means that the remainder of the paragraph is only relevant for people who do not understand or agree with your initial statement. All other readers can just skip to the next paragraph. For instance
Citation-proximity analysis suffers from the same problems as other citation-based approaches for calculating document relatedness. This problem relates to the necessity that documents must be cited before document relatedness can be calculated. However, the majority of research papers is not cited at all [3]. In addition, it takes usually a year or longer before a paper receives its first citation [4]. This means, citation-based document relatedness can only be calculated for few documents in a corpus, and typically only for documents being published some time ago. ← Someone being familiar with citation analysis, will know all this already. However, some other readers might not.
- For those who are still not convinced, you provide an example and more evidence.
Citation-proximity analysis suffers from the same problems as other citation-based approaches for calculating document relatedness. This problem relates to the necessity that documents must be cited before document relatedness can be calculated. However, the majority of research papers is not cited at all [3]. In addition, it takes usually a year or longer before a paper receives its first citation [4]. This means, citation-based document relatedness can only be calculated for few documents in a corpus, and typically only for documents being published some time ago. For instance, in our Mr. DLib recommender system, only12% of the documents are co-cited at least once, and only 3.8% of documents are co-cited more than five times [5]. Among the recent documents being published in the past two years, only 0.4% of documents are co-cited more than five times. This means, Mr. DLib can use citation-based recommendation approaches only for a small fraction of its documents. ← If a reader still hasn’t understood by now that citation-proximity analysis has some disadvantages when it comes to calculating document relatedness… well, then there is no hope for that person.
You should always (!) keep this in mind, whatever you write. Especially providing examples is super important. An example can also be a screenshot of a GUI or some other illustration. You must be aware that if a reader does not get what you are saying, the reader most likely will not like your work and lose interest.
Balanced length
In a well written document, each paragraph has around the same length and the longest paragraph might be maybe twice as long as the shortest. If not, it is very likely that the document is not well written and hence difficult to understand. Just make a little experiment when you read your next papers. After reading a paper, decide if you found the paper easy to understand or not. Then zoom out and have a look how balanced the paragraphs are. I am sure, you will find a very high correlation between “ease of reading” and “balance of paragraph length. But, of course, your own paper is not becoming better by just merging two short paragraphs into one normal-length paragraph. Each paragraph must still follow the SEXI rule, and each paragraph should only be about one SEXI statement.
- Good

- Bad



Short sentences
Make your sentences short. Especially, if you are not a native English speaker!
In the 2-column ACM format, 1.5 or 2 lines should be the standard. Never more than 3 lines!

In the 1-column ACM or Springer format, 1 or 1.5 lines should be the standard. Never more than 2.5 lines

Avoid brackets
In academic writing there is a simple rule: If something is important, don’t put it in brackets. If something is not important, don’t put it in the paper.
Use Active Voice / Avoid Passive Voice
Make it crystal clear who did or said something: Always use active voice, never passive voice.
Bad: It was shown that…
Good: We showed that… (or “Author ABC showed that…”)
Be consistent in your terminology
If you use a certain term (e.g. “item”) then don’t use a different term for the same thing in the next sentence (e.g. “resource”). Look at this example:
Digital libraries provide millions of resources such as books and academic articles. To find such relevant items, the libraries often offer a keyword search. An alternative to discover relevant objects are recommender systems.
The sentence above is difficult to understand because a reader needs to think each time “hm… is an item the same as a resource and is that the same as an object? Much easier to understand is this:
Digital libraries provide millions of resources such as books and academic articles. To find such relevant resources, the libraries often offer a keyword search. An alternative to discover relevant resources are recommender systems.
Another example
“Position bias” describes the tendency of users to interact with items on top of a list with higher probability than with items at a lower rank,
Using once “top of a list” and once “lower rank” is slightly irritating. It would be better to write “items on top of a list […] items at the bottom of a list” or “items at a higher rank […] items at a lower rank”.
(Relative) Numbers, numbers, and numbers
Whenever possible, provide precise numbers, ideally percentages.
Bad: “Many of the reviewed recommender systems apply content-based filtering”
Better: “23 of the reviewed recommender systems apply content-based filtering”
Good: “68% of the reviewed recommender systems apply content-based filtering”
Best: “68% (23) of the reviewed recommender systems apply content-based filtering”
Words to Avoid
“very”, “a lot”, “much better/worse” …
Avoid vague terms like “very”, “much”, “a lot”, and “some”. Instead, provide specific numbers and let your reader doing the judging. For instance, when you write “algorithm A was much more effective than algorithm B”, one reader may think “ok, algorithm A probably was around 10% more effective than algorithm B”. Another one may think that algorithm A was 50% more effective than algorithm B. Hence, it’s better to write “algorithm x was 31% more effective then algorithm Y with an accuracy of 0.46 vs. 0.60 “. The reader himself can then decide if this is “somewhat better”, “a lot better”, or “fucking mindblowing”.
Also, generally, avoid the term “very”. It is almost never needed.
“however”
Sometimes, using “however” makes sense. However, in most situations, you can just delete it and the meaning of the sentence remains the same. However, if you use “however”, ensure that the sentence containing “however” is really a contradiction to the previous sentence. For instance:
Apples are usually green.
However, they taste good. ← However makes no sense here, unless you believe that green things usually taste bad.
Apples are usually green. However, there are also red ones.
Never start a new paragraph with ‘however’!
“Obviously”, “clearly”, “evident”, “of course”, …
Never use the word “obvious”: If something is obvious, then, obviously, you don’t need to say it. If you feel you need to say it, then it’s not obvious.
Also words like “evident” and “of course” are dangerous and typically superfluous. They are particularly dangerous if the reader disagrees with you. If you write “The data shows that algorithm X performed better than Z”, but the reader disagrees for some reason (because the results have low statistical significance, because whatever) then the reader’s disagreement will be even stronger when you write “The data shows clearly…”.
… using machine learning…
When choosing a title, do not write something like “… using machine learning…”. This sounds as if you just took some machine learning algorithm, applied it to your data, and waited to see what came out. Even if that’s what you did, you shouldn’t make it so obvious in the title. Your title should create the impression that you created something new. For instance:
Bad: Doing X using Deep Learning
Better: A Convolutional Neural Network Architecture for X
Abstract terms like “object”, “item”, “entity”, “resource”, “class”…
Some nouns describe very vague concepts and every reader may have their own understanding of them. For instance, when you write…
“Digital libraries provide many resources“.
… different people will have a different understanding of “resources”. A researcher in recommender systems in digital libraries may think of digital books and research articles when reading the term “resources”. The IT manager of a library may think about desks and computers when reading “resources”. The HR manager of a digital library may think of employees.
Therefore, ideally avoid such vague terms. If you need to use it, provide examples of what you mean:
“Digital libraries provide many resources such as books and research articles
or
“Digital libraries provide many resources such as desk space, computers, and offices to their students.
Words to be Careful With
Reference-terms like “this” or “they”
When you reference a previous object with “this” or “they” or “he”, be 100% sure that the reader understands whom you are referring to. For instance:
Digital libraries provide millions of books. They are …
In this example, it is not immediately clear what “They” is referring to – the libraries or the books? In this example it would be much easier to read if you wrote:
Digital libraries provide millions of books. These books are …
or
Digital libraries provide millions of books. The libraries are …”
Sometimes, you can avoid such situations by not writing twice in the plural (or singular) but once in singular and once in the plural. For instance:
A digital library typically provides millions of books. They are… [clearly refering to the books]
A digital library typically provide millions of books. It is… [clearly refering to a library]
Most importantly, if you use a term like “this”, then you must have previously mentioned something that “this” refers to. For instance, read the following example
[…] The A/B engine records all details about the algorithms, as well as additional information such as when a request was received, when the response was returned, and if a recommendation was clicked. All this information is contained in the dataset. For a more detailed description of Mr. DLib’s architecture and algorithms, please refer to Beel, Aizawa, et al. [2017], Beel and Dinesh [2017a; 2017b], Beel, Dinesh, et al. [2017], Beierle et al. [2017], Feyer et al. [2017] and Siebert et al. [2017].
3 RELATED WORK
This has been downloaded from Github [Beel et al., 2017]. […]
In the above text, it remains unclear what “This” refers to. In addition, a new section (e.g. Related Work) should never ever start with “This”, even if you have mentioned some object in the previous section. You must assume that a reader just starts reading the current section without knowing what has been mentioned in the previous one.
Conclusions (“Therefore”, “Because”)
If you have a chain of arguments, then double and triple check that the arguments are plausible and build upon each other.
Hyphens and Compound Adjectives / Nouns
Use hyphens to ease the reading, and clarify the meaning of words. For instance, when you write “English language learner” (no hyphens), a reader will not know if you are talking about a person that is English and learns another language (English Language-Learner), or if you are referring to a person that learns English (“English-Language Learner). The meaning only becomes clear if you use hyphens.
More details on hyphenation here: https://www.grammarbook.com/punctuation/hyphens.asp
Multiple “example word” such as “such as”, “etc.”, “for instance”
If you provide examples there is no need to write:
Digital libraries such as ACM, SpringerLink, IEEE Xplore, etc. face many challenges .
Each of the words “such as” and “etc” indicates an example and it is sufficient to use one of them
Digital libraries such as ACM, SpringerLink, and IEEE Xplore face many challenges.
OR
The digital libraries ACM, SpringerLink, IEEE Xplore, etc. face many challenges.
“As mentioned previously”
Avoid writing “as mentioned previously”. In short documents, this is never necessary. In long documents, it might be necessary but there are more elegant ways than writing “as mentioned previously”. Also, if you use it, specify where this was mentioned previously.
Bad: As mentioned previously, there is lots of work on recommender system but no work has used graph-based neural networks. Our recommendation approach is first to use a graph-based neural network in the context of recommender system.
Good: Our recommendation approach uses a graph-based neural network. To the best of our knowledge (cf. ´Related Work´, p. 34) we are first to do this.
Abbreviations
Use words that people know and search for. This means, avoid uncommon abbreviations because it will
- make your paper harder to read
- make your manuscript less well indexed in Google Scholar. For instance, many people will search for “research-paper recommender systems” on Google Scholar, but no one will search for “RPRS” or “RePaReSy”.
However, if you introduce a new concept, for instance, “Citation Proximity Analysis”, then you should use an abbreviation (CPA), because you will use it throughout the paper, and hopefully other people will adopt this new abbreviation in the future.
If you have to use abbreviations, then highlight them in the text, so readers can find them more easily. For instance
For the online evaluation, 57,050 recommendations were delivered to 1,311 users. The primary evaluation metric was click-through rate (CTR). We also calculated mean average precision (MAP) over the recommendation sets. This means, for each set of recommendations (typically ten), the average precision was calculated. For example, when two of ten recommendations were clicked, average precision was 0.2. Subsequently, the mean was calculated over all recommendation sets of a particular algorithm.
For the offline evaluation, we removed the paper that was last downloaded from a user’s document collection together with all mind maps and mind map nodes that were created by the user after downloading the paper. An algorithm was randomly assembled to generate ten recommendations and we measured the recommender’s precision, i.e. whether the recommendations contained the removed paper. Performance was measured as precision at rank ten (P@10). The evaluation was based on 5,021 mind maps created by 1,491 users.
Figures (Color, Labels, Data Table, …)
Cross-reference figures in the body text
When you add figures to your paper (and you should add plenty of them), then you must reference them from within the text (see figure below).

Explain figures
Do not just write things like “Figure 4 shows how the algorithms performed” and then proceed to the next result. Instead, always explain exactly what a figure is showing and what can be seen. Be as precise as possible. For instance, look at this figure:
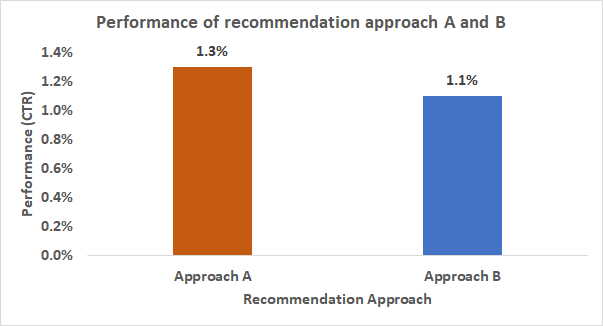
Bad:
“Figure 1 shows the performance of the evaluated recommendation algorithms.” ← This is a vague statement and does not contain any information that is not immedeately visible from the figure itself already (everyone reading the caption of the figure will know that this figure shows the performane of the evaluated recommendation approaches). So, basically, the entrire statement is redundant with the figure caption.
Mediocre:
“Algorithm A outperformed Algorithm B (Figure 1)” ← This is better because it has less words than the above description but provides more information. Imagine, a reader who doesn’t know what CTR is. From the above description the reader wouldn’t know, which of the two approaches performed better.
Good:
“Algorithm A outperformed Algorithm B with a CTR of 1.3% vs. 1.1% (Figure 1)” ← This sentence explains that approach A was better than B and why you think it was better than B. However, it still is too vague because it does not answer what “better than” exactly means. Does it mean ”just a little bit’, or twice as performant? Or 100 times as performant?
Best:
“Algorithm A was 18% more performant than Algorithm B with a CTR of 1.3% vs. 1.1% (Figure 1)” ← The information that A was 18% more performant than B is some highly valuable information that a) cannot easily be seen from the figure and b) quantifies the rather general statement that A was more performant than B.
You may think that it is pretty obvious from the figure that approach A is better than B and why it is better. But imagine more complex charts like this:

In such a chart, it would be much more difficult to understand e.g. which approach was best and why. Hence, you need to explain it (even for simple figures)!
Use different patterns (for B/W printing)
Believe it or not but there are people who are still printing papers and they might print black-and-white. Therefore, when you use colours in your paper, use different patterns for bar charts and lines (e.g. dotted and dashed lines).
- Bad (imagine how this will look when you print it black-and-white):
- Good:
Don’t use green and red (for colour blind people)
Many scientists have difficulties to distinguish between green and red. Hence, avoid using green and red in the same figure.
Provide specific numbers
You want others to understand precisely what your results are. To enable them, provide specific numbers either as a label or as a data table.
- Bad (readers have to approximate what e.g. precision for Algorithm A was)
- Good (readers can see the exact numbers; though you don’t need labels and a data table; pick one of the two options)

Start the y-axis at 0
Some researchers like to skip the first numbers on the y-axis, which then strengthens the visual effect of their data. Do not do that!
- Bad (y-axis starts at 90)
- Good (y-axis stars at 0)
Label the x and y-axis
- Bad (no labels at the axes)
- Good

Shrink the y-axis as far as possible (don’t waste space)
Usually, space is limited in a research paper. Hence don’t accept the standard size for a figure that e.g. Excel is suggesting. You can easily modify a figure’s height and save lots of space
- Bad
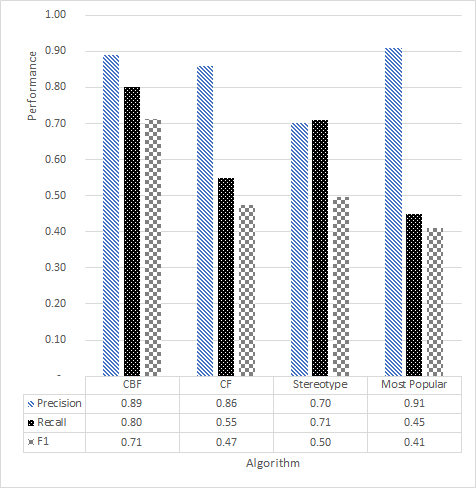
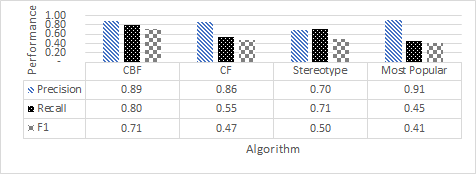
- Good
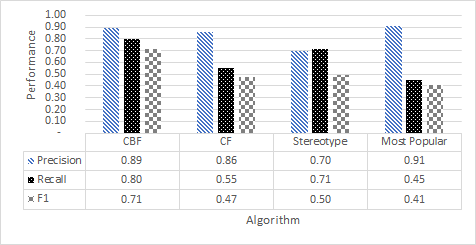
- Also ok (if you need the space)
Use Vector graphics instead of bitmaps
If you don’t know why vector graphics are superior to bitmaps, Google it https://www.google.ie/search?q=difference+between+vector+and+bitmap&oq=difference+between+vector. If you don’t know, how to create and insert vector graphics in Microsoft Word, read on.
To add a figure (or table) from MS Excel in MS Word as vector graphic, do the following
- Select the figure in Excel
- Press CTRL+C
- Go to MS Word
- Press CRL+SHIFT+V
- The “Paste Special” dialogue pops out. You select “Picture (Enhanced Metafile”)
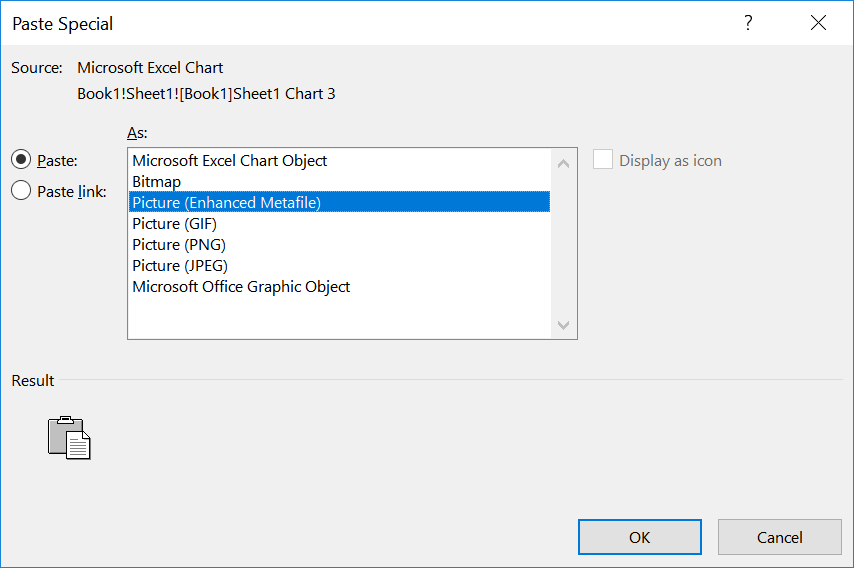
Please note, the “Enhanced Metafile” format is always to prefer over Bitmap, PNG, JPEG etc. if the source data is in vector format. It’s also to prefer over the “Excel Chart object” or similar.
Here is an example of how vector and bitmap/jpeg differ, especially when you zoom in (click to enlarge the image)

Authorship
Who becomes an author?
Everyone who contributes to a manuscript becomes an author. The most notable contributions are providing an idea, writing the manuscript, providing data, and doing data analysis. Programming something is not necessarily a contribution in itself (exception: demo papers). Persons who have not contributed enough to be an author but still helped doing the work, should be mentioned in the acknowledgements.
If you are not sure, who should be listed as an author, ask your supervisor. It is very important that you do not forget anyone. Although, of course, you should not “spoil” the list of authors, the worst thing that could happen is that a person is not listed as an author who feels he/she should have been listed. In that case, the person probably has little interest to support you in the future.
Author Order
In computer science the first author is typically the author who authored the manuscript and/or the person that contributed most to the paper (ideally it’s the same person, then there won’t be any discussions). A supervisor is typically the last author, at least if the ‘only’ contribution of the supervisor was the supervision. If the supervisor wrote the manucript, he/she will be first author. Otherwise, authors are ranked by the impact of their contribution. Please note that contribution != invested time.
Responsibilities
The first author is responsible that everything works out fine, i.e. deadlines are kept, other co-authors do what they are supposed to do, the paper is properly formatted and submitted, and eventually presented at the conference.
Post-Writing
Promoting your Work
https://www.elsevier.com/connect/get-found-optimize-your-research-articles-for-search-engines
0 Comments