We released a new version of RARD, i.e. RARD II and describe the new release in a preprint published on arXiv. The dataset is available at http://data.mr-dlib.org and the new manuscript is available on arXiv and here in our Blog.
The main contribution of this paper is to introduce and describe a new recommender-systems dataset (RARD II). It is based on data from a recommender-system in the digital library and reference management software domain. As such, it complements datasets from other domains such as books, movies, and music. The RARD II dataset encompasses 89m recommendations, covering an item-space of 24m unique items. RARD II provides a range of rich recommendation data, beyond conventional ratings. For example, in addition to the usual rating matrices, RARD II includes the original recommendation logs, which provide a unique insight into many aspects of the algorithms that generated the recommendations. In this paper, we summarise the key features of this dataset release, describing how it was generated and discussing some of its unique features.
1. INTRODUCTION
The availability of large-scale, realistic, and detailed datasets is an essential element of many research communities, such as the information retrieval (e.g. TREC [1,2], NTCIR [3,4], and CLEF [5,6]), machine learning (UCI [7], OpenML [8], KDD Cup [9]) and recommender systems community. Such datasets provide data for researchers to benchmark existing techniques, as well as develop and evaluate new algorithms. They can also be essential when it comes to supporting the development of a research community. Indeed, the recommender-systems community has been well-served by the availability of a number of datasets in popular domains including movies [10,11], books [12], music [13] and news [5,14]. The importance of these datasets is evidenced by their popularity among researchers and practitioners; for example, the MovieLens datasets have been downloaded 140,000 times in 2014 [10], and, as of April 2018, Google Scholar lists some 13,000 research articles and books that mention one or more of the MovieLens datasets [15].
The recommender-systems community has matured, and the importance of recommender systems has grown rapidly in the commercial arena. Researchers and practitioners alike have started to look beyond the traditional e-commerce/entertainment domains (e.g. books, music, and movies). It is with this demand in mind that we introduce the RARD II dataset. RARD II is based on a digital-library recommender-as-a-service platform known as Mr. DLib [16–18]. Primarily, Mr. DLib provides related-article type recommendations based some source/query articles, to a number of partner services including the social-sciences digital library Sowiport [19–22] and the JabRef reference-management software [23].
The unique value of RARD II, for recommender systems research, stems from the scale and variety of data that it provides in the domain of digital libraries. RARD II includes data from 89m recommendations, originating from more than 12m queries. Importantly, in addition to conventional ratings-type data, RARD II includes comprehensive recommendation logs. These provide a detailed account of the recommendations that were generated – not only the items that were recommended, but also the context of the recommendation (the source query and recommendation destination), and meta-data about the algorithms and parameters used to generate them.
In what follows, we describe this RARD II data release in more detail. We provide information about the process that generated the dataset, and pay particular attention to a number of the unique features of this dataset.
2. Background / Mr. DLib
Mr. DLib is a recommendation-as-a-service (RaaS) provider [16]. It is designed to suggest related articles through partner services such as digital libraries or reference management applications. For example, Mr. DLib provides related-article recommendations to Sowiport to be presented on Sowiport´s website alongside some source/target article (see Figure 1). Sowiport is the largest social science digital library in Germany, with a corpus of 10m articles.
In another use-case, Mr. DLib provides related-article recommendations to JabRef, one of the most popular open-source reference managers (Figure 2) [24]. Briefly, when users select a reference/article in JabRef, the “related articles” tab presents a set of related-articles, retrieved from Mr. DLib. Related-article recommendations are made from the 10m Sowiport corpus, and 14m CORE documents [25–28].
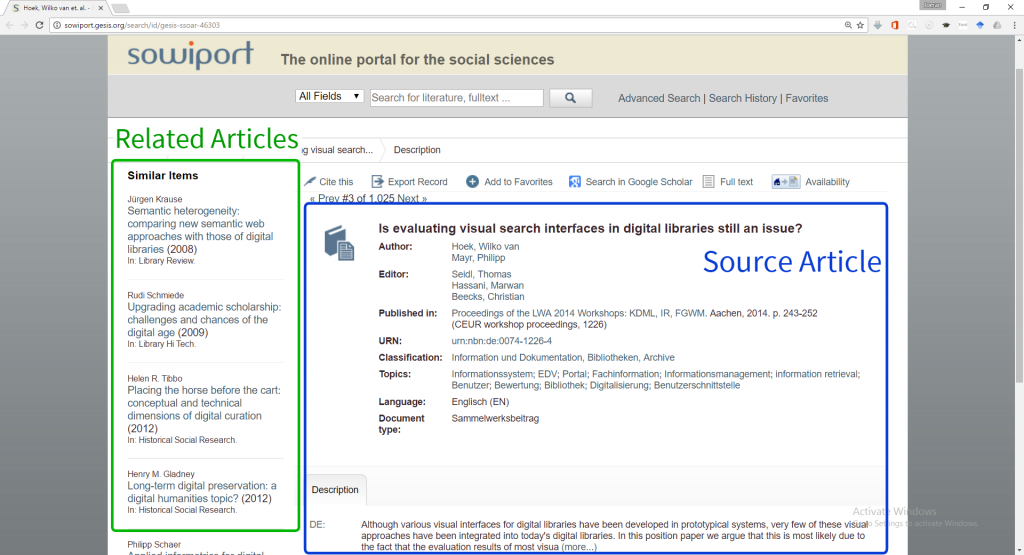
Figure 1: Sowiport’s website with a source-article (blue) and related-article recommendations (green)
Figure 3 summarises the recommendation process, implemented as a Restful Web Service. The starting point for Mr. DLib to calculate recommendations is the id or title of some source article. Importantly, Mr. DLib closes the recommendation loop because in addition to providing recommendations to a user, the response of a user (principally, article selections) is returned to Mr. DLib for logging.
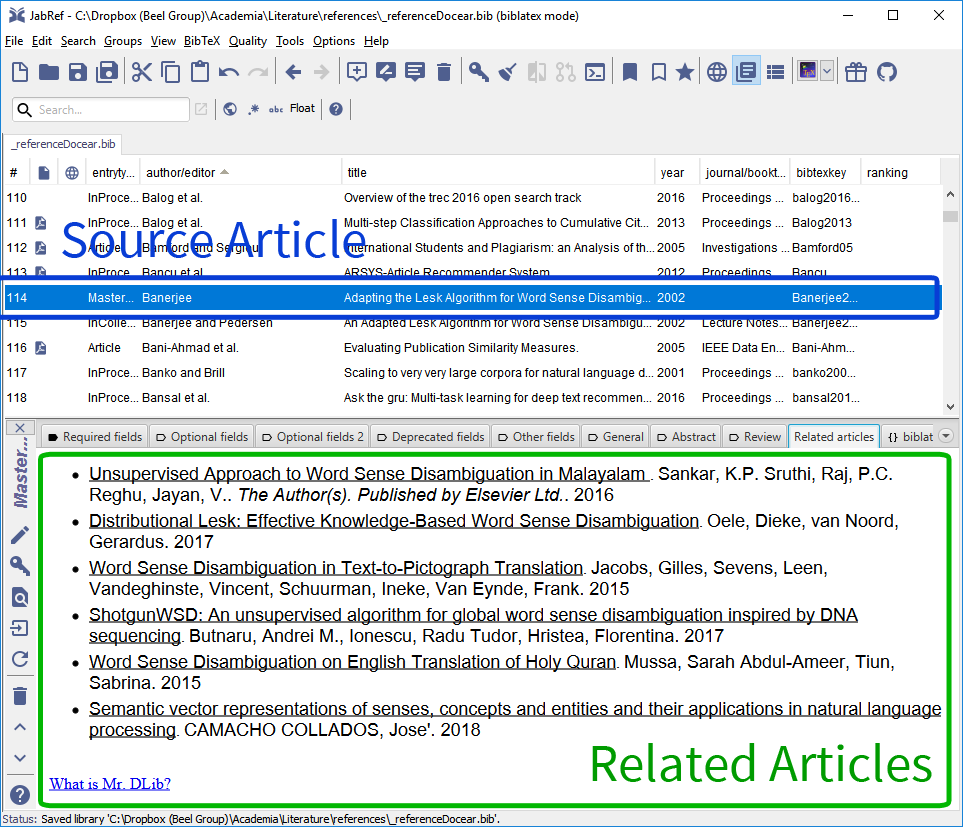
Figure 2: Related-article recommendations in JabRef
To generate a set of recommendation, Mr. DLib harnesses different recommendation approaches including content-based filtering. Mr. DLib also uses external recommendation APIs such as the CORE Recommendation API [29,30]. The algorithm selection and parametrization is managed by Mr. DLib’s A/B testing engine. The details of the recommendation approach used, including any relevant parameters and configurations, are logged by Mr. DLib.

Figure 3: Illustration of the recommendation process
As an example of the data that Mr. DLib logs, when the A/B engine chooses content-based filtering, it randomly selects whether to use ‘normal keywords’, ‘key-phrases’ [31] or ‘word embeddings’. For each option, additional parameters are randomly chosen; e.g., when key-phrases are chosen, the engine randomly selects whether key-phrases from the ‘title’ or ‘abstract’ are used. Subsequently, the system randomly selects whether unigrams, bigrams, or trigrams are used. Then, the system randomly selects how many key-phrases to use to calculate document relatedness [1…20]. The A/B engine also randomly chooses which matching mode to use when parsing queries [standardQP | edismaxQP]. Finally, the engine selects whether to re-rank recommendations with readership data from Mendeley, and how many recommendations to return.
All this information – the queries and responses, user actions, and the recommendation process meta data – is made available in the RARD II data release.
3. The RARD II Dataset
RARD II is available on http://data.mr-dlib.org and published under “Creative Commons Attribution 3.0 Unported (CC-BY)” license [32].
In this section we summarise the key characteristics of the RARD II release, which consists of three sub-datasets: (1) the recommendation log; (2) the ratings matrices; and (3) the original document IDs. Compared to its predecessor RARD I [33], RARD II contains 56% more recommendations, 187% more features (algorithms, parameters, and statistics), 57% more clicks, 140% more documents, and one additional service partner (i.e. JabRef).
3.1 The Recommendation Log
The recommendation_log.csv file (19 GB) contains details on each related-article query from Sowiport and JabRef, and the individual article recommendations returned by Mr. DLib. A detailed description of every field in the recommendation log is beyond the scope of this short paper (please refer to the dataset’s documentation for full details). Briefly, Figure 4 illustrates the structure of the recommendation log. The key statistics of the log are presented in Table 1, and a few key numbers are explained in the following.
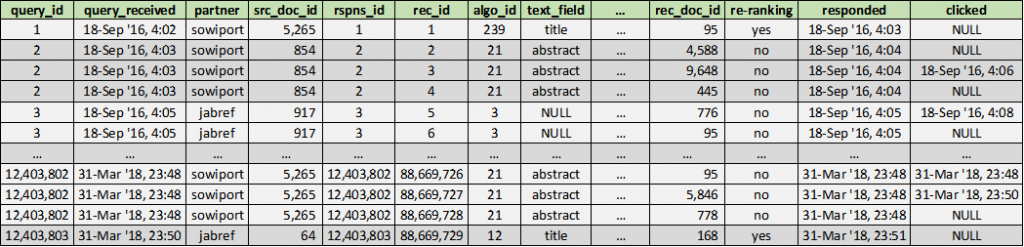
Figure 4: Illustration of the recommendation log
The log contains 89,470,575 rows, and each row corresponds to a single recommended item, i.e. a related-article. All items were returned in one of the 12,532,801 responses to the 12,532,801 queries by Sowiport and JabRef. The 12.5m queries were made for 2,417,002 unique source documents (out of the 24m documents in the corpus). This means, for each of the 2.4m documents, recommendations were requested 5.2 times on average. For around 21.6m documents in the corpus, recommendations were never requested.
Each of the 12.5m responses contains between one and 15 related-article recommendations – 89m recommendations in total and 7.15 on average per response. The 89m recommendations were made for 6,910,224 unique documents out of the 24m documents in the corpus. This means, those documents that were recommended, were recommended 12.8 times on average. Around 17m documents in the corpus were never recommended.
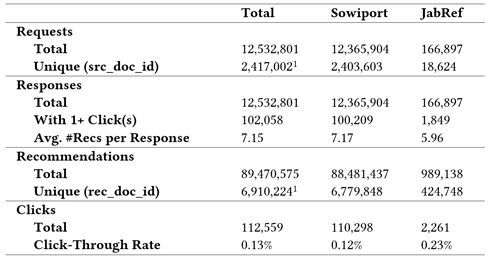
Table 1: Key numbers of the recommendation log
For each recommended article, the recommendation log contains more than 40 features (columns) including:
- Information about the partner, query article, and time.
- The id of the recommendation response, recommended articles, and various ranking information before and after Mr. DLib’s A/B selection.
- Information about the recommendation technique used, including algorithm features (relevancy and popularity metrics, content features where relevant) and the processing time needed to generate these recommendations.
- The user response (a click/selection, if any) and the time of this response.
The log includes 112,559 clicks received for the 89m recommendations, which equals a click-through rate (CTR) of 0.13%. 102,058 of the 12m responses contained at least one clicked recommendation (0.8%). It is worth noting that there are various user-interface factors that influence this click-through rate from the destination services that are beyond the scope of this article. Suffice it to say that the Mr. DLib recommendations are typically presented in a manner that is designed not to distract the user, which no doubt tends to reduce the CTR. On the other hand, the fact that users need to ‘work’ to select a recommendation may suggest that these selections provide a more reliable source of implicit feedback than might otherwise be the case.
RARD II’s recommendation log enables researchers to reconstruct the fine details of these historic recommendation sessions, and the responses of users, for the purpose of benchmarking and/or evaluating new article recommendation strategies.
3.2 The Implicit Ratings Matrices
A ratings matrix is a mainstay of most recommendation datasets. RARD II contains two implicit, item-item rating matrices discussed below. Implicit ratings are based on the assumption that when users click a recommended article it is because they find the recommendation relevant (a positive rating). And, conversely if they don’t click a recommendation it is because the recommendation is not relevant (a negative rating). Of course, neither of these assumptions is particularly reliable. For example, just because a user selects a recommendation doesn’t mean it will turn out to be relevant. Likewise, a user may choose not to respond if a recommendation is not relevant, or they may simply not notice the recommendation. However, click-related metrics such as click-through rate are a commonly used metric, particularly in industry, and are a good first indication of relevance.
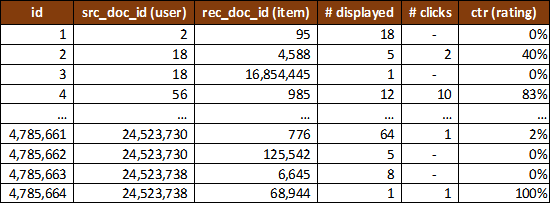
Figure 5: Illustration of the full rating matrix
The full ratings matrix rating_matrix_full.csv (1.7 GB) is illustrated in Figure 5. It contains 47,249,570 rows, one for each <source document; recommended document> tuple. For each tuple, the following information is provided.
- The id of the source document (src_doc_id) for which Sowiport or JabRef queried recommendations. In a typical recommendation scenario, this entity may be interpreted as the user to whom recommendations were made.
- The id of a related-article (rec_doc_id) that was returned for the query. This entity may be interpreted as the item that was recommended to the ‘user’.
- The number of times (#displayed) the tuple occurs in the recommendation log, i.e. how often the article was recommended as related to the given source document.
- The number of times the recommended article was clicked by a user (#clicks).
- The click-through rate (CTR), which represents an implicit rating of how relevant the recommended document was for the given source document.
The full rating matrix was computed based on the full recommendation log. Hence, it also includes data from responses for which none of the recommendations were clicked. There are at least three reasons why users sometimes did not click on any recommendation: users may not have liked any of the recommendations; users may not have seen the recommendation; or recommendations may have been delivered to a web spider or bot. In the latter two cases, the non-clicks should not be interpreted as a negative vote. However, it is not possible to identify, which of the three scenarios applies for those sets in which no recommendation was clicked. Therefore, we created a filtered rating matrix.
The filtered ratings matrix rating_matrix_filtered.csv (25 MB) contains 733,367 rows (Figure 6) and has the same structure as the full ratings matrix. However, the matrix is based only on responses in which at least one recommendation from the response was clicked. The rationale is that when at least one recommendation was clicked, a real user must have looked at the recommendations who decided to click some recommendations and to not click others. Consequently, the non-clicked recommendations are more likely to correspond to an actual negative vote. Compared to the full matrix, the rows are missing that represent <source document; recommended document> tuples that were delivered in responses that did not receive any clicks. Also, the remaining rows tend to have lower #displayed counts than in the full-ratings matrix.
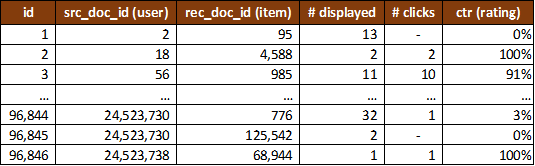
Figure 6: Illustration of the filtered rating matrix
3.3 External IDs (Sowiport, Mendeley, arXiv, …)
The third element of the data release is the list of external document ids (external_IDs.csv, 280 MB). There are 24.5m such ids for the Sowiport and CORE documents used. In addition, for a subset of the Sowiport ids there is associated identifiers for Mendeley (18%), ISSN (16%), DOI (14%), Scopus IDs (13%), ISBN (11%), PubMed IDs (7%) and arXiv IDs (0.4%). This third subset is provided to facilitate researchers in obtaining additional document data and meta-data from APIs provided by Sowiport [34], CORE [35], and Mendeley [36].
4. Discussion
We have introduced RARD II, a large-scale, richly detailed dataset for recommender systems research based on more than 89m delivered scientific article recommendations. It contributes to a growing number of such datasets, most focusing on ratings data, ranging in scale from a few thousand datapoints to tens or even hundreds of millions of datapoints [37].
The domain of the RARD II data release (article recommendation) distinguishes it from more common e-commerce domains, but it is not unique in this regard; see for example [38,39]. Also, CiteULike [40,41] and Bibsonomy [42,43] published datasets containing the social tags that their users added to research articles and, although not intended specifically for use in recommender systems research, these datasets have nonetheless been used to evaluate research-paper recommender systems [44–52]. In related work, Jack et al. compiled a Mendeley dataset [53] based on 50,000 randomly selected personal libraries from 1.5m users and with 3.6m unique articles. Similarly, Docear published a dataset based on its recommender system [54] based on the metadata of 9.4m articles, their citation network, related user information, and the details of 300,000 recommendations.
While RARD II shares some similarities with some of these datasets, particularly Docear, it is one of the only examples of a dataset from the digital library domain that has been specifically designed to support recommender systems research. Because of this, it includes information that is especially valuable to recommender systems researchers, not just ratings data but also the recommendation logs, which provide a unique insight into all aspects of the sessions that generated the recommendations and led to user clicks. Considering the scale and variety of data, RARD II is a unique and valuable addition to existing datasets.
5. Limitations & Future Work
RARD II is a unique dataset with high value to recommender-systems researchers, particularly in the domain of digital libraries. However, we see many areas for improvement, which we plan to address in the future.
Currently, RARD only contains data from Mr. DLib, and Mr. DLib delivers recommendations only to two partners. We hope to include data from more recommendation services in the future in addition to Mr. DLib. Potential candidates would be, for instance, Babel [55] and CORE [30] who provide services similar to Mr. DLib. Additional partners of Mr. DLib could also increase the value of the RARD releases.
RARD would also benefit from having personalized recommendation algorithms included in addition to the non-personalized related-article recommendations. We are also aware of the limitations that clicks inherit as evaluation metrics. Future versions of RARD will include additional metrics such as real user ratings, or other implicit metrics. For instance, knowing whether a recommended document was eventually added to a JabRef user’s library would provide valuable information. While RARD contains detailed information about the applied algorithms and parameters, information about the items is limited. We hope to be able to include more item-related data in future releases (in particular metadata such as author names and document titles).
To implement the suggested improvements, a sustainable and continuous development is needed. Fortunately, we recently received a grant that allows hiring two full-time software engineers and researchers for two years. This grant will allow implementing most, if not all, of the outlined improvements.
REFERENCES
[1] D. Harman, “Overview of the First Text REtrieval Conference (TREC-1),” NIST Special Publication 500-207: The First Text REtrieval Conference (TREC-1), 1992.
[2] E.M. Voorhees and A. Ellis, eds., The Twenty-Fifth Text REtrieval Conference (TREC 2016) Proceedings, National Institute of Standards and Technology (NIST), 2016.
[3] A. Aizawa, M. Kohlhase, and I. Ounis, “NTCIR-10 Math Pilot Task Overview.,” NTCIR, 2013.
[4] R. Zanibbi, A. Aizawa, M. Kohlhase, I. Ounis, G. Topi, and K. Davila, “NTCIR-12 MathIR task overview,” NTCIR, National Institute of Informatics (NII), 2016.
[5] F. Hopfgartner, T. Brodt, J. Seiler, B. Kille, A. Lommatzsch, M. Larson, R. Turrin, and A. Serény, “Benchmarking news recommendations: The clef newsreel use case,” ACM SIGIR Forum, ACM, 2016, pp. 129–136.
[6] M. Koolen, T. Bogers, M. Gäde, M. Hall, I. Hendrickx, H. Huurdeman, J. Kamps, M. Skov, S. Verberne, and D. Walsh, “Overview of the CLEF 2016 Social Book Search Lab,” International Conference of the Cross-Language Evaluation Forum for European Languages, Springer, 2016, pp. 351–370.
[7] D. Dheeru and E. Karra Taniskidou, “UCI Machine Learning Repository,” University of California, Irvine, School of Information and Computer Sciences. http://archive.ics.uci.edu/ml, 2017.
[8] J. Vanschoren, J.N. van Rijn, B. Bischl, and L. Torgo, “OpenML: Networked Science in Machine Learning,” SIGKDD Explorations, vol. 15, 2013, pp. 49–60.
[9] SIGKDD, “KDD Cup Archives,” ACM Special Interest Group on Knowledge Discovery and Data Mining. http://www.kdd.org/kdd-cup, 2018.
[10] F.M. Harper and J.A. Konstan, “The movielens datasets: History and context,” ACM Transactions on Interactive Intelligent Systems (TiiS), vol. 5, 2016, p. 19.
[11] S. Dooms, A. Bellog?n, T.D. Pessemier, and L. Martens, “A Framework for Dataset Benchmarking and Its Application to a New Movie Rating Dataset,” ACM Trans. Intell. Syst. Technol., vol. 7, 2016, pp. 41:1–41:28.
[12] C.-N. Ziegler, S.M. McNee, J.A. Konstan, and G. Lausen, “Improving recommendation lists through topic diversification,” Proceedings of the 14th international conference on World Wide Web, ACM, 2005, pp. 22–32.
[13] T. Bertin-Mahieux, D.P.W. Ellis, B. Whitman, and P. Lamere, “The Million Song Dataset,” Proceedings of the 12th International Conference on Music Information Retrieval (ISMIR 2011), 2011.
[14] B. Kille, F. Hopfgartner, T. Brodt, and T. Heintz, “The plista dataset,” Proceedings of the 2013 International News Recommender Systems Workshop and Challenge, ACM, 2013, pp. 16–23.
[15] Google, “Search Results Mentioning MovieLens on Google Scholar,” https://scholar.google.de/scholar?q=“movielens”. Retrieved 14 April 2018, 2018.
[16] J. Beel, A. Aizawa, C. Breitinger, and B. Gipp, “Mr. DLib: Recommendations-as-a-Service (RaaS) for Academia,” Proceedings of the ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL), 2017, pp. 1–2.
[17] J. Beel and S. Dinesh, “Real-World Recommender Systems for Academia: The Gain and Pain in Developing, Operating, and Researching them,” Proceedings of the Fifth Workshop on Bibliometric-enhanced Information Retrieval (BIR) co-located with the 39th European Conference on Information Retrieval (ECIR 2017), P. Mayr, I. Frommholz, and G. Cabanac, eds., 2017, pp. 6–17.
[18] J. Beel, B. Gipp, S. Langer, M. Genzmehr, E. Wilde, A. Nürnberger, and J. Pitman, “Introducing Mr. DLib, a Machine-readable Digital Library,” Proceedings of the 11th ACM/IEEE Joint Conference on Digital Libraries (JCDL‘11), ACM, 2011, pp. 463–464.
[19] D. Hienert, F. Sawitzki, and P. Mayr, “Digital library research in action – -supporting information retrieval in Sowiport,” D-Lib Magazine, vol. 21, 2015.
[20] P. Mayr, “Sowiport User Search Sessions Data Set (SUSS),” GESIS Datorium, 2016.
[21] F. Sawitzki, M. Zens, and P. Mayr, “Referenzen und Zitationen zur Unterstützung der Suche in SOWIPORT,” Internationales Symposium der Informationswissenschaft (ISI 2013). Informationswissenschaft zwischen virtueller Infrastruktur und materiellen Lebenswelten, DEU, 2013, p. 5.
[22] M. Stempfhuber, P. Schaer, and W. Shen, “Enhancing visibility: Integrating grey literature in the SOWIPORT Information Cycle,” International Conference on Grey Literature, 2008, pp. 23–29.
[23] O. Kopp, U. Breitenbücher, and T. Müller, “CloudRef – Towards Collaborative Reference Management in the Cloud,” Proceedings of the 10th Central European Workshop on Services and their Composition, 2018.
[24] J. Beel, “On the popularity of reference managers, and their rise and fall,” Docear Blog. https://www.isg.beel.org/blog/2013/11/11/on-the-popularity-of-reference-managers-and-their-rise-and-fall/, 2013.
[25] P. Knoth and N. Pontika, “Aggregating Research Papers from Publishers’ Systems to Support Text and Data Mining: Deliberate Lack of Interoperability or Not?,” Proceedings of INTEROP2016, INTEROP2016, 2016.
[26] P. Knoth and Z. Zdrahal, “CORE: three access levels to underpin open access,” D-Lib Magazine, vol. 18, 2012.
[27] N. Pontika, P. Knoth, M. Cancellieri, and S. Pearce, “Developing Infrastructure to Support Closer Collaboration of Aggregators with Open Repositories,” LIBER Quarterly, vol. 25, Apr. 2016.
[28] L. Anastasiou and P. Knoth, “Building Scalable Digital Library Ingestion Pipelines Using Microservices,” Proceedings of the 11th International Conference on Metadata and Semantic Research (MTSR), Springer, 2018, p. 275.
[29] P. Knoth, L. Anastasiou, A. Charalampous, M. Cancellieri, S. Pearce, N. Pontika, and V. Bayer, “Towards effective research recommender systems for repositories,” Proceedings of the Open Repositories Conference, 2017.
[30] N. Pontika, L. Anastasiou, A. Charalampous, M. Cancellieri, S. Pearce, and P. Knoth, “CORE Recommender: a plug in suggesting open access content,” http://hdl.handle.net/1842/23359, 2017.
[31] F. Ferrara, N. Pudota, and C. Tasso, “A Keyphrase-Based Paper Recommender System,” Proceedings of the IRCDL’11, Springer, 2011, pp. 14–25.
[32] Creative Commons, “Creative Commons Attribution 3.0 Unported (CC BY 3.0),” https://creativecommons.org/licenses/by/3.0/, 2018.
[33] J. Beel, Z. Carevic, J. Schaible, and G. Neusch, “RARD: The Related-Article Recommendation Dataset,” D-Lib Magazine, vol. 23, Jul. 2017, pp. 1–14.
[34] GESIS, “Sowiport OAI API,” http://sowiport.gesis.org/OAI/Home, 2017.
[35] CORE, “CORE Open API and Datasets,” https://core.ac.uk, 2018.
[36] Mendeley, “Mendeley Developer Portal (Website),” http://dev.mendeley.com/, 2016.
[37] A. Gude, “The Nine Must-Have Datasets for Investigating Recommender Systems,” Blog. https://gab41.lab41.org/the-nine-must-have-datasets-for-investigating-recommender-systems-ce9421bf981c, 2016.
[38] M. Lykke, B. Larsen, H. Lund, and P. Ingwersen, “Developing a test collection for the evaluation of integrated search,” European Conference on Information Retrieval, Springer, 2010, pp. 627–630.
[39] K. Sugiyama and M.-Y. Kan, “Scholarly paper recommendation via user’s recent research interests,” Proceedings of the 10th ACM/IEEE Annual Joint Conference on Digital Libraries (JCDL), ACM, 2010, pp. 29–38.
[40] CiteULike, “Data from CiteULike’s new article recommender,” Blog, http://blog.citeulike.org/?p=136, Nov. 2009.
[41] K. Emamy and R. Cameron, “Citeulike: a researcher’s social bookmarking service,” Ariadne, 2007.
[42] D. Benz, A. Hotho, R. Jäschke, B. Krause, F. Mitzlaff, C. Schmitz, and G. Stumme, “The Social Bookmark and Publication Management System BibSonomy,” The VLDB Journal, vol. 19, 2010, pp. 849–875.
[43] Bibsonomy, “BibSonomy :: dumps for research purposes.,” https://www.kde.cs.uni-kassel.de/bibsonomy/dumps/, 2018.
[44] C. Caragea, A. Silvescu, P. Mitra, and C.L. Giles, “Can’t See the Forest for the Trees? A Citation Recommendation System,” iConference 2013 Proceedings, 2013, pp. 849–851.
[45] R. Dong, L. Tokarchuk, and A. Ma, “Digging Friendship: Paper Recommendation in Social Network,” Proceedings of Networking & Electronic Commerce Research Conference (NAEC 2009), 2009, pp. 21–28.
[46] Q. He, J. Pei, D. Kifer, P. Mitra, and L. Giles, “Context-aware citation recommendation,” Proceedings of the 19th international conference on World wide web, ACM, 2010, pp. 421–430.
[47] W. Huang, S. Kataria, C. Caragea, P. Mitra, C.L. Giles, and L. Rokach, “Recommending citations: translating papers into references,” Proceedings of the 21st ACM international conference on Information and knowledge management, ACM, 2012, pp. 1910–1914.
[48] S. Kataria, P. Mitra, and S. Bhatia, “Utilizing context in generative bayesian models for linked corpus,” Proceedings of the 24th AAAI Conference on Artificial Intelligence, 2010, pp. 1340–1345.
[49] D.M. Pennock, E. Horvitz, S. Lawrence, and C.L. Giles, “Collaborative filtering by personality diagnosis: A hybrid memory-and model-based approach,” Proceedings of the Sixteenth conference on Uncertainty in artificial intelligence, Morgan Kaufmann Publishers Inc., 2000, pp. 473–480.
[50] L. Rokach, P. Mitra, S. Kataria, W. Huang, and L. Giles, “A Supervised Learning Method for Context-Aware Citation Recommendation in a Large Corpus,” Proceedings of the Large-Scale and Distributed Systems for Information Retrieval Workshop (LSDS-IR), 2013, pp. 17–22.
[51] R. Torres, S.M. McNee, M. Abel, J.A. Konstan, and J. Riedl, “Enhancing digital libraries with TechLens+,” Proceedings of the 4th ACM/IEEE-CS joint conference on Digital libraries, ACM New York, NY, USA, 2004, pp. 228–236.
[52] F. Zarrinkalam and M. Kahani, “SemCiR – A citation recommendation system based on a novel semantic distance measure,” Program: electronic library and information systems, vol. 47, 2013, pp. 92–112.
[53] K. Jack, M. Hristakeva, R.G. de Zuniga, and M. Granitzer, “Mendeley’s Open Data for Science and Learning: A Reply to the DataTEL Challenge,” International Journal of Technology Enhanced Learning, vol. 4, 2012, pp. 31–46.
[54] J. Beel, S. Langer, B. Gipp, and A. Nürnberger, “The Architecture and Datasets of Docear’s Research Paper Recommender System,” D-Lib Magazine, vol. 20, 2014.
[55] I. Wesley-Smith and J.D. West, “Babel: A Platform for Facilitating Research in Scholarly Article Discovery,” Proceedings of the 25th International Conference Companion on World Wide Web, International World Wide Web Conferences Steering Committee, 2016, pp. 389–394.
[1] The sum of ‘Sowiport’ and ‘JabRef’ does not equal the ‘Total’ number because some documents were requested by / recommended to both Sowiport and JabRef. However, these documents are only counted once for the ‘Total’ numbers.



0 Comments