
Abstract. Many recommender-system datasets are pruned, i.e. some data is removed that wouldn’t be removed in a production recommender-system. For instance, the MovieLens dataset contains only data from users who rated 20 or more movies.1 Similarly, some researchers prune data themselves and conduct their experiments only on subsets of the original data, sometimes as little as 0.58% of the original data. We conduct a study to find out how often pruned data is used for recommender system research, and what the effect of data pruning is. We find that 40% of researchers used pruned recommender system datasets for their research, and 15% pruned data themselves. MovieLens is the most used dataset (40%) and can be considered as a defacto standard dataset. Based on MovieLens, we found that removing users with less than 20 ratings is equivalent to removing 5% of ratings and 42% of users. Performance differs widely for different user groups. Users with less than 20 ratings have an RMSE of 1.03 on average, i.e. 23% worse than users with 20+ ratings (0.84). Ignoring these users may not be always ideal. We discuss the results and conclude that pruning should be avoided, if possible, though more discussion in the community is needed.
@INPROCEEDINGS{Beel2019e,
author = {Beel, Joeran and Brunel, Victor},
title = {Data Pruning in Recommender Systems Research: Best-Practice or Malpractice?},
booktitle = {13th ACM Conference on Recommender Systems (RecSys)},
year = {2019},
}
Introduction
’Data pruning’ is a common practice in recommender-systems research. We define data pruning as the removal of instances from a dataset that would not be removed in the real-world, i.e. when used by recommender systems in production environments. Reasons to prune datasets are manifold and include user interests or laws when publishing data (e.g. data privacy) or business interests. ’Data pruning’ differs from ’data cleaning’ as such that data cleaning is typically a prerequisite for the effective training of recommender-system and machine-learning algorithms (e.g. outlier removal), whereas data pruning is not affecting the algorithm performance in itself.
A prominent example of data pruning is the MovieLens (ML) dataset in most of its variations1 [3]. The MovieLens dataset(s) contain information about how users of MovieLens.org rated movies. When creating the MovieLens dataset, the MovieLens team decided to exclude ratings of users who rated less than 20 movies.1 The reasoning was as follows:2
“(1) for most purposes, [researchers] needed enough ratings to evaluate algorithms, since most studies needed a mix of training and test data, and it is always possible to use a subset of data when you want to study low-rating cases; and (2) the movies receiving the first ratings for users during most of MovieLens’ history are biased based on whatever algorithm was in place for new-user startup (for most of the site’s life, that was a mix of popularity and entropy), hence the MovieLens team didn’t want to include users who hadn’t gotten past the ’start-up’ stage into rating movies through normal use.”
Joseph A. Konstan (2019), one of the MovieLens founders.2
Not only the creators of datasets may prune data, but also individual researchers may do so. For instance, Caragea et al. pruned the CiteSeer corpus for their research [2]. The corpus contains a large number of research articles and their citations. Caragea et al. removed research papers with fewer than ten and more than 100 citations as well as papers citing fewer than 15 and more than 50 research papers. From originally 1.3 million papers in the corpus, around 16,000 remained (1.2%). Similarly, Pennock et al. removed many documents so that only 0.58% remained for their research [6].
We criticized the practice of data pruning previously, particularly when only a fraction of the original data remains [1]. We argued that evaluations based on a small fraction of the original data are of little significance. For instance, knowing that an algorithm performs well for 0.58% of users is of little significance if it remains unknown how the algorithm performs for the remaining 99.42%.
Also, it is well known that collaborative filtering tends to perform poorly for users with few ratings [5]. Hence, when evaluating collaborative filtering algorithms, we would consider it crucial to not ignore users with few ratings, i.e. those users for whom the algorithms presumably perform poorly.
Our previous criticism was more based on ’gut feeling’ than scientific evidence. To the best of our knowledge, no empirical evidence exists on how widely data pruning is applied, and how data pruning affects recommender-systems evaluations. Also, the recommender-system community has never widely discussed if, how and to what extent a) datasets should be pruned by their creators and b) whether individual researchers should prune data. In this paper, we conduct the first steps towards answering these questions. Ultimately, we hope to stimulate a discussion that eventually leads to widely accepted guidelines on pruning data for recommender-systems research.

Methodology
To identify how widespread data pruning is, we analyzed a total of 112 full- and short papers from the ACM Conference on Recommender Systems (RecSys) 2017 and 2018. Of these 112 papers, 88 papers (79%) used offline datasets, the remaining 24 papers (21%) did not use datasets and instead conducted e.g. user studies or online evaluations. For the 88 papers, we analyzed, which datasets the researchers used, whether these datasets were pruned by the original creators and whether researchers conducted (additional) pruning. To identify the latter part, we read the Methodology sections of the manuscripts (or similarly named sections)3. Please note that this analysis was done by a single person rather quickly. Consequently, there might be a few errors, and the reported numbers should be seen as ballpark figures.
To identify the effect of data pruning on the outcome of recommender-system evaluations, we run six collaborative filtering algorithms from the Surprise library [4], namely SVD, SVD++, NMF, Slope One, Co-Clustering, and the Baseline Estimator. We use the ’MovieLens Latest Full’ dataset (Sept. 2018). It contains 27 million ratings by 280,000 users including data from users with less than 20 ratings, i.e. the dataset is not pruned. Due to computing constraints, we use a random sample with 6,962,757 ratings made by 70,807 users.4
We run the six algorithms on three sub-sets of the dataset, i.e. for a) the entire unpruned dataset, b) the data that would be included in a ’normal’ version of MovieLens, i.e. only users with 20+ ratings c) the data that would be ’normally’ not included in the MovieLens dataset (users with less than20 ratings). We then compare how algorithms perform on these different sets. We measured the performance of algorithms by Mean Absolute Error (MAE) and Root Mean Square Error (RMSE). As the two metrics led to almost identical results, we only report RMSE. Our source code is available at https://github.com/BeelGroup/recsys-dataset-pruning. We also publish the Excel sheet with details on the datasets used in the 88 research papers.
Result
The popularity of (Pruned) Recommender-Systems Datasets
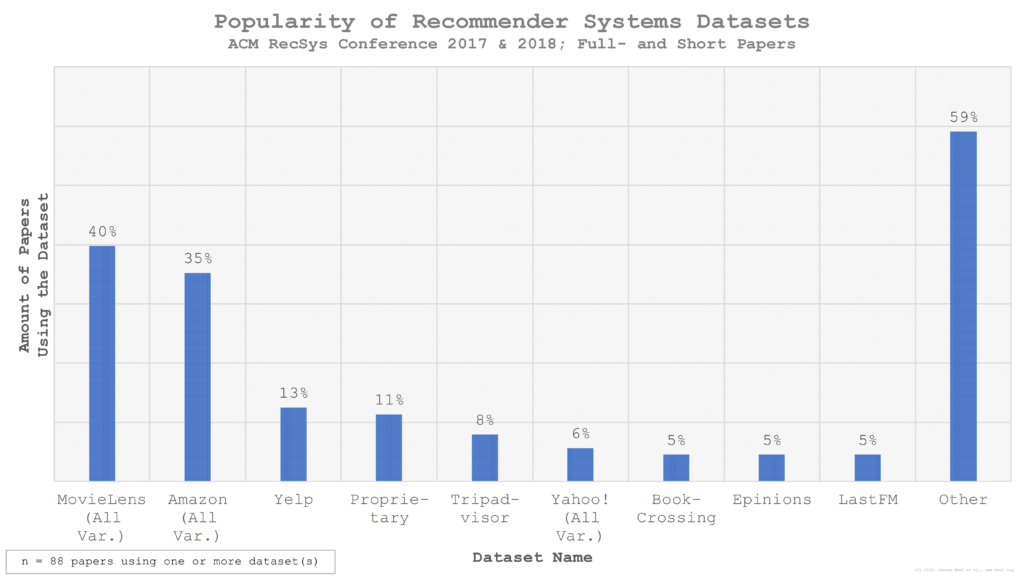
The authors of the 88 papers used a total of 64 unique datasets, whereas we counted different variations of MovieLens, Amazon and Yahoo! as the same dataset. Our analysis empirically confirms what is common wisdom in the recommender-system community already: MovieLens is the de-facto standard dataset in recommender-systems research. 40% of the full- and short papers at RecSys 2017 and 2018 used the MovieLens dataset in at least one of its variations (Figure 3). The second most popular dataset is Amazon, which was used by 35% of all authors. Other popular datasets are shown in Figure 3 and include Yelp (13%), Tripadvisor (8%), Yahoo! (6%), BookCrossing (5%), Epinions (5%), and LastFM (5%). 11% of all researchers used a proprietary dataset, and 2% used a synthetic dataset.
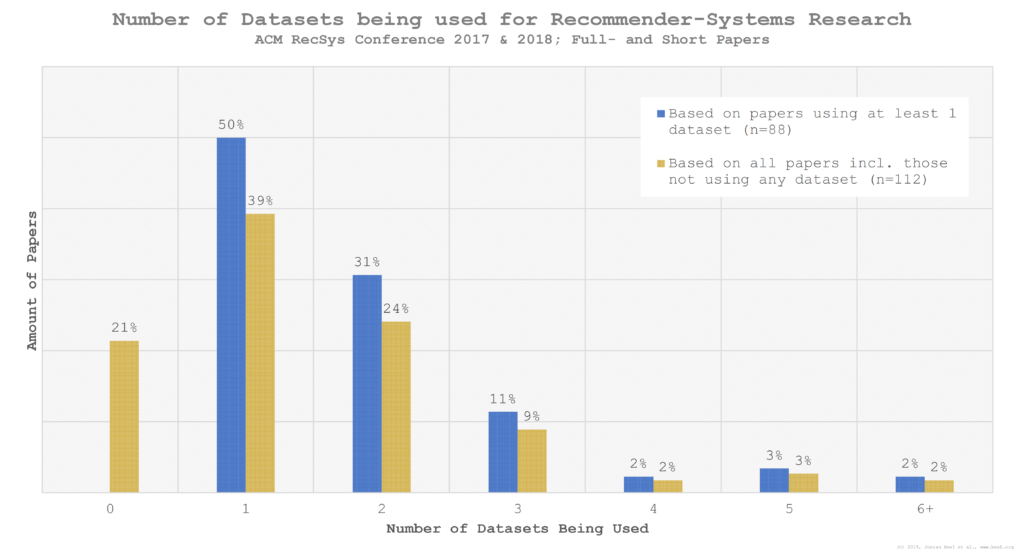
50% of the researchers conducted their research with a single dataset (if researchers used multiple variations of e.g. MovieLens, we counted this as one dataset), 31% used two datasets, and only 2% used six or more datasets (Figure 4). The highest number of datasets being used was 7. On average the researchers used 1.88 datasets. 40% used a pruned dataset (mostly MovieLens), and 15% of the authors pruned datasets themselves. In total, 48% of all authors conducted their research at least partially with pruned data.
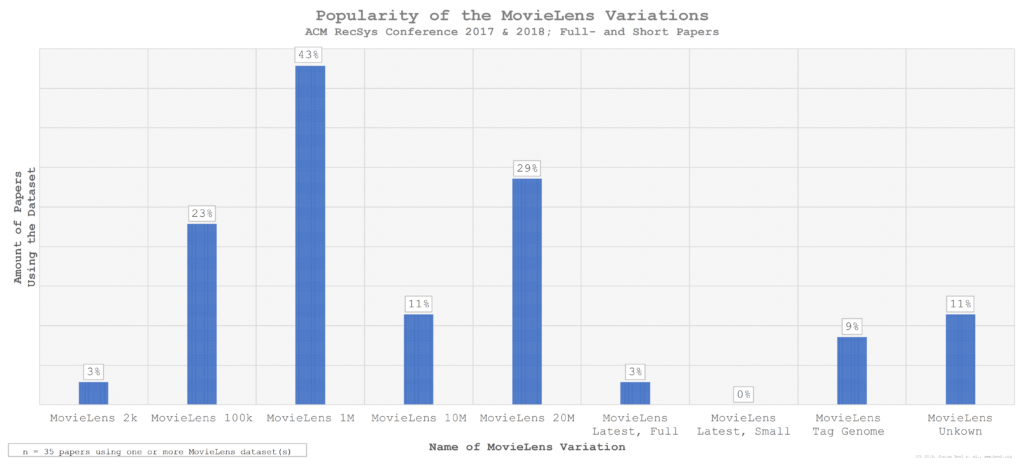
Of those 35 manuscripts that used one (or several) MovieLens datasets, MovieLens 1m was the most popular MovieLens variation (43%), i.e. of those researchers using some MovieLens dataset, 43% choose the MovieLens 1m dataset, and possibly additional variations (Figure 5). MovieLens 20m was the second most popular variation (29%), and MovieLens 100k the third most popular variation (23%). One author (3%) used the unpruned MovieLens Latest, Full dataset, which, according to MovieLens, is not recommended for research.1 No one used the MovieLens Latest, Small dataset. 11% of those researchers using MovieLens did not specify, which variation they used.
The Effect of Data Pruning
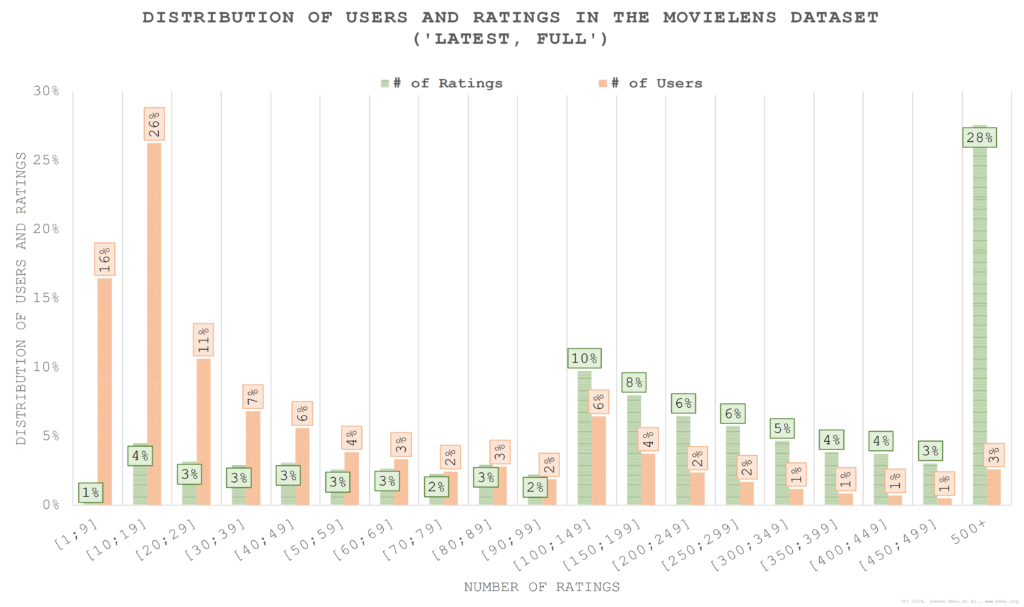
The user-rating distribution in MovieLens follows a typical long-tail distribution (Figure 1). 42% of the users in the unpruned MovieLens dataset have less than 20 ratings, and these users contribute 5% of all ratings. The remaining 58% of users with 20+ ratings contribute 95% of all ratings in the dataset. The top 3% of users – those with 500+ ratings – contribute 28% of all ratings in the dataset. Consequently, using a pruned MovieLens variation (100k, 1m, …) means ignoring around 5% of the ratings and ignoring around 42% of users.5
There are notable differences between the three data splits in terms of algorithm performance (Figure 2). Over the entire unpruned data, RMSE of the six algorithms is 0.86 on average, with the best algorithm being SVD++ (0.80), closely followed by SVD (0.81). The worst performing algorithm is Co-Clustering (0.90). For the subset of users with 20+ ratings – that equals a ’normal’ MovieLens dataset – RMSE over all algorithms is 0.84 on average (2.12% lower, i.e. better). In other words, using a pruned version of MovieLens will lead, on average, to a 2.12% better RMSE compared to using the unpruned data. But, to make this very clear, the algorithms do not actually perform 2.12% better. The results only appear to be better because data – for which the algorithms perform rather poorly – was excluded in the evaluation. The ranking of the algorithms remains the same when comparing the pruned with the unpruned data (SVD++ performs best, followed by SVD, and Co-Clustering performs worst).

The previous analysis focused on predicting as many ratings as possible correctly. However, we also looked at the users grouped by the number of ratings per user.6 Figure 6 shows the RMSE for the data in this case. Follow-up research is needed to confirm the numbers, and investigate different options. users with 1-9 ratings, 10-19 ratings, … 500+ ratings. There is a constant improvement (i.e. decrease) in RMSE the more ratings user have. On average, the six algorithms achieve an RMSE of 1.03 for users with less than 20 ratings (1.07 for users with <=9 ratings; 1.02 for users with 10–19 ratings). This contrasts an average RMSE of 0.84 for users with 20 and more ratings. In other words, RMSE for users in a pruned MovieLens dataset is 23% better than RMSE for the excluded users. For SVD and SVD++, the best performing algorithms, this effect is even stronger (+27% for SVD; +25% for SVD++).
Discussion & Future Work
Data Pruning is a widespread phenomenon with 48% of short- and full papers at RecSys 2017 and 2018 being based at least partially on pruned data. The MovieLens dataset nicely illustrates an issue that probably applies to many datasets with user-rating data. In the pruned MovieLens datasets, the number of removed ratings is rather small (5%). However, these 5% ratings were made by 42% of the users. For researchers focusing on how well individual ratings can be predicted, this limitation has probably little impact. For researchers who focus on user-specific issues, ignoring 42% of users is probably not ideal, particularly as their RMSE is 23% worse than the RMSE of the users with 20+ ratings who are usually used for research.
When discussing data pruning, the probably most important question is whether pruning changes the ranking of the evaluated algorithms. The answer – in our study – is ’no, the ranking does not change’. The algorithm that was best (second best…) on the pruned MovieLens data was also best (second best…) on the unpruned dataset. However, other research has already shown that the ranking may change, though that research was not conducted in the context of data pruning [5].7 It seems likely to us that rankings are more likely to change if more diverse algorithms are compared such as collaborative filtering vs. content-based filtering. Also, the MovieLens dataset is relatively moderately pruned. We consider it quite likely that heavy pruning, where only a small fraction remains (e.g. Pennock et al. [6]), might lead to a change in the ranking of algorithms. More research with more diverse algorithms, different datasets, and different degrees of pruning is needed though to confirm or reject that assumption. Also, a qualitative study could be helpful to identify more details on the motivation why dataset creators and individual researchers prune data.
Given the current results, we propose that data pruning should be applied with great care, or, if possible, be avoided. We would not generally consider pruning as malpractice, but certainly not a best-practice either. In some cases, especially when large parts of data are removed, data pruning may become malpractice, though the community yet has to determine how much removed data is too much. As a starting point, we would recommend the following guidelines, though this is certainly not a definite recommendation, and more discussion in the community is needed:
- Publishers of datasets should avoid pruning – if possible. If there are compelling reasons to prune data (e.g. ensuring privacy), these should be clearly communicated in the documentation.
- Researchers using a pruned dataset, should discuss and highlight the implications that this may have on their results.
- Individual researchers should not prune data. If researchers feel that their algorithm may perform particularly well on a subset of the data, they should report performance for both the entire dataset and the subset). If researchers conduct pruning, they should clearly indicate this in the manuscript as a limitation, provide reasoning, and discuss potential implications.
It may not always be obvious where data cleaning ends, legitimate data pruning begins, and when data pruning becomes malpractice. The community certainly needs more discussion about this issue. We are confident that with widely agreed guidelines on data pruning, recommender-systems research will become more reproducible, more comparable and more representative of ’the real world’.
Acknowledgments
This publication has emanated from research conducted with the financial support of Science Foundation Ireland (SFI) under Grant Number 13/RC/2106 and funding from the European Union and Enterprise Ireland under Grant Number CF 2017 0303-1.
Footnotes
1 The ’MovieLens Latest Full’ dataset is not pruned. All other variations of MovieLens are pruned (100k, 1m, 10m, …). However, ’Movie-Lens Latest Full’ is not recommended for research as it is changing over time.
2 Quote from our email exchange with Joseph A. Konstan, one of the MovieLens founders. Permission to quote from the email was granted.
3 We might have missed some relevant information on pruning if that information was provided in a section other than the Methodology section.
4 For users with only 1 rating, ’Surprise’ uses a special technique for evaluations. Please also note that using a random sample is not an example of data pruning.
5 The actual numbers in the pruned MovieLensversions may somewhat differ given that we just used a sample, and the different MovieLens versions differ due to the fact that they include data from different time periods.
6 It is actually not trivial to decide how to split the data in this case. Follow-up research is needed to confirm the numbers, and investigate different options.
7 The authors evaluated different collaborative filtering variations (user-user, item-item, …). For users with very few ratings (<8), other algorithms performed best than for users with more than 8 ratings.
References
[1] Joeran Beel, Bela Gipp, Stefan Langer, and Corinna Breitinger. 2016. Research Paper Recommender Systems: A Literature Survey. International Journal on Digital Libraries 4 (2016), 305–338. https://doi.org/10.1007/s00799-015-0156-0
[2] Cornelia Caragea, Adrian Silvescu, Prasenjit Mitra, and C Lee Giles. 2013. Can’t See the Forest for the Trees? A Citation Recommendation System. In iConference. 849–851. https://doi.org/10.9776/13434
[3] F Maxwell Harper and Joseph A Konstan. 2016. The movielens datasets: History and context. ACM Transactions on Interactive Intelligent Systems (TiiS) 5, 4 (2016), 19.
[4] Nicolas Hug. 2017. Surprise, a Python library for recommender systems. http://surpriselib.com (2017).
[5] Daniel Kluver and Joseph A Konstan. 2014. Evaluating recommender behavior for new users. In Proceedings of the 8th ACM Conference on Recommender Systems. ACM, 121–128.
[6] David M Pennock, Eric Horvitz, Steve Lawrence, and C Lee Giles. 2000. Collaborative filtering by personality diagnosis: A hybrid memory-and model-based approach. In the Sixteenth Conference on Uncertainty in Artificial Intelligence. 473–480.



0 Comments