 Which one is the best reference management software? That’s a question any student or researcher should think about quite carefully, because choosing the best reference manager may save lots of time and increase the quality of your work significantly. So, which reference manager is best? Zotero? Mendeley? Docear? …? The answer is: “It depends”, because different people have different needs. Actually, there is no such thing as the ‘best’ reference manager but only the reference manager that is best for you (even though some developers seem to believe that their tool is the only truly perfect one).
Which one is the best reference management software? That’s a question any student or researcher should think about quite carefully, because choosing the best reference manager may save lots of time and increase the quality of your work significantly. So, which reference manager is best? Zotero? Mendeley? Docear? …? The answer is: “It depends”, because different people have different needs. Actually, there is no such thing as the ‘best’ reference manager but only the reference manager that is best for you (even though some developers seem to believe that their tool is the only truly perfect one).
In this Blog-post, we compare Zotero, Mendeley, and Docear and we hope that the comparison helps you to decide which of the reference managers is best for you. Of course, there are many other reference managers. Hopefully, we can include them in the comparison some day, but for now we only have time to compare the three. We really tried to do a fair comparison, based on a list of criteria that we consider important for reference management software. Of course, the criteria are subjectively selected, as are all criteria by all reviewers, and you might not agree with all of them. However, even if you disagree with our evaluation, you might find at least some new and interesting aspects as to evaluate reference management tools. You are very welcome to share your constructive criticism in the comments, as well as links to other reviews. In addition, it should be obvious that we – the developers of Docear – are somewhat biased. However, this comparison is most certainly more objective than those that Mendeley and other reference managers did ;-).
Please note that we only compared about 50 high-level features and used a simple rating scheme in the summary table. Of course, a more comprehensive list of features and a more sophisticated rating scheme would have been nice, but this would have been too time consuming. So, consider this review as a rough guideline. If you feel that one of the mentioned features is particularly important to you, install the tools yourself, compare the features, and share your insights in the comments! Most importantly, please let us know when something we wrote is not correct. All reviewed reference tools offer lots of functions, and it might be that we missed one during our review.

Please note that the developers of all three tools constantly improve their tools and add new features. Therefore, the table might be not perfectly up-to-date. In addition, it’s difficult to rate a particular functionality with only one out of three possible ratings (yes; no; partly). Therefore, we highly suggest to read the detailed review, which explains the rationale behind the ratings.
The table above provides an overview of how Zotero, Mendeley, and Docear support you in various tasks, how open and free they are, etc. Details on the features and ratings are provided in the following sections. As already mentioned, if you notice a mistake in the evaluation (e.g. missed a key feature), please let us know in the comments.
Overview
If you don’t want to read a lot, just jump to the summary
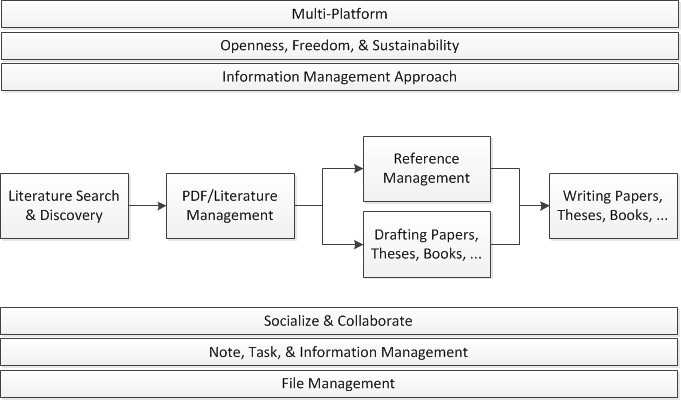
We believe that a reference manager should offer more features than simple reference management. It should support you in (1) finding literature, (2) organizing and annotating literature, (3) drafting your papers, theses, books, assignments, etc., (4) managing your references (of course), and (5) writing your papers, theses, etc. Additionally, many – but not all – students and researchers might be interested in (6) socializing and collaboration, (7) note, task, and general information management, and (8) file management. Finally, we think it is important that a reference manager (9) is available for the major operating systems, (10) has an information management approach you like (tables, social tags, search, …), and (11) is open, free, and sustainable (see also What makes a bad reference manager).
(more…)


")
 vs. Mean Absolute Error (MAE) vs Mean Squared Error (MSE) vs Root Mean Squared Error (RMSE) vs Precision")