Update 2019-05-25: Google integrates our NTM implementation in the official TensorFlow release.
Update 2018-10-20: Official publication available at SpringerLink
Update: 2018-10-06: Our paper received the best-paper award at ICANN.
We have released an open source implementation of a Neural Turing Machine for TensorFlow, and published on arXiv the corresponding paper which we will present at ICANN 2018. Neural Turing Machines are notoriously difficult to implement and train. Our contribution is to explain why previous implementations have not successfully replicated the results in the original Neural Turing Machines paper. We then went on and produced an open source implementation which trains reliably and quickly. The work was done as part of my undergraduate thesis in the group of Prof Joeran Beel at the School of Computer Science and Statistics and the ADAPT Centre at Trinity College Dublin.
We published the implementation and pre-print only a few days ago, and have received considerable interest from the machine learning community. This includes 305 stars on GitHub and a Tweet by David Ha (Google Brain) on Twitter with over 500 likes and 200 retweets (“After 4 years, someone finally implemented a stable version of NTM”).
David Ha (Google Brain) on Twitter about our paper and implementation https://twitter.com/hardmaru/status/1021901750268096512
Below you find a copy of the manuscript. You can cite it as follows
@InProceedings{CollierBeel2018,
author = {Collier, Mark and Beel, Joeran},
title = {Implementing Neural Turing Machines},
booktitle = {27th International Conference on Artificial Neural Networks (ICANN)},
year = {2018},
editor = {K{\r{u}}rkov{\’a}, V{\v{e}}ra and Manolopoulos, Yannis and Hammer, Barbara and Iliadis, Lazaros and Maglogiannis, Ilias},
part = {3},
volumes = {11141},
series = {Lecture Notes in Computer Science},
publisher = {Springer International Publishing},
isbn = {978-3-030-01424-7},
pages = {94–104},
doi = {10.1007/978-3-030-01424-7_10},
abstract = {Neural Turing Machines (NTMs) are an instance of Memory Augmented Neural Networks, a new class of recurrent neural networks which decouple computation from memory by introducing an external memory unit. NTMs have demonstrated superior performance over Long Short-Term Memory Cells in several sequence learning tasks. A number of open source implementations of NTMs exist but are unstable during training and/or fail to replicate the reported performance of NTMs. This paper presents the details of our successful implementation of a NTM. Our implementation learns to solve three sequential learning tasks from the original NTM paper. We find that the choice of memory contents initialization scheme is crucial in successfully implementing a NTM. Networks with memory contents initialized to small constant values converge on average 2 times faster than the next best memory contents initialization scheme.},
}
Abstract
Neural Turing Machines (NTMs) are an instance of Memory Augmented Neural Networks, a new class of recurrent neural networks which decouple computation from memory by introducing an external memory unit. Neural Turing Machines have demonstrated superior performance over Long Short-Term Memory Cells in several sequence learning tasks. A number of open source implementations of Neural Turing Machines exist but are unstable during training and/or fail to replicate the reported performance of Neural Turing Machines. This paper presents the details of our successful implementation of a Neural Turing Machine. Our implementation learns to solve three sequential learning tasks from the original Neural Turing Machine paper. We find that the choice of memory contents initialization scheme is crucial in successfully implementing a Neural Turing Machine. Networks with memory contents initialized to small constant values converge on average 2 times faster than the next best memory contents initialization scheme.
1 Introduction
Neural Turing Machines (NTMs) [4] are one instance of several new neural network architectures [4,5,11] classified as Memory Augmented Neural Networks (MANNs). MANNs defining attribute is the existence of an external memory unit. This contrasts with gated recurrent neural networks such as Long ShortTerm Memory Cells (LSTMs) [7] whose memory is an internal vector maintained over time. LSTMs have achieved state-of-the-art performance in many commercially important sequence learning tasks, such as handwriting recognition [2], machine translation [12] and speech recognition [3]. But, MANNs have been shown to outperform LSTMs on several artificial sequence learning tasks that require a large memory and/or complicated memory access patterns, for example memorization of long sequences and graph traversal [4,5,6,11].
The authors of the original Neural Turing Machine paper, did not provide source code for their implementation. Open source implementations of Neural Turing Machines exist
- https://github.com/snowkylin/ntm
- https://github.com/chiggum/Neural-Turing-Machines
- https://github.com/yeoedward/Neural-Turing-Machine
- https://github.com/loudinthecloud/pytorch-ntm
- https://github.com/camigord/Neural-Turing-Machine
- https://github.com/snipsco/ntm-lasagne
- https://github.com/carpedm20/NTM-tensorflow
but a number of these implementations report that the gradients of their implementation sometimes become NaN during training, causing training to fail. While others report slow convergence or do not report the speed of learning of their implementation.
The lack of a stable open source implementation of Neural Turing Machines makes it more difficult for practitioners to apply Neural Turing Machines to new problems and for researchers to improve upon the NTM architecture. In this paper we define a successful Neural Turing Machine implementation which learns to solve three benchmark sequential learning tasks [4].
We specify the set of choices governing our NTM implementation. We conduct an empirical comparison of a number of memory contents initialization schemes identified in other open source NTM implementations. We find that the choice of how to initialize the contents of memory in a NTM is a key factor in a successful NTM implementation. We base our Tensorflow implementation on another open source Neural Turing Machine implementation , but following our experimental results make significant changes to the memory contents initialization, controller head parameter computation and interface which result in faster convergence, more reliable optimization and easier integration with existing Tensorflow methods. Our implementation is available publicly under an open source license.
2 Neural Turing Machines
Neural Turing Machines consist of a controller network which can be a feed-forward neural network or a recurrent neural network and an external memory unit which is a N ∗ W memory matrix, where N represents the number of memory locations and W the dimension of each memory cell. Whether the controller is a recurrent neural network or not, the entire architecture is recurrent as the contents of the memory matrix are maintained over time.
The controller has read and write heads which access the memory matrix. The effect of a read or write operation on a particular memory cell is weighted by a soft attentional mechanism. This addressing mechanism is similar to attention mechanisms used in neural machine translation [1,9] except that it combines location based addressing with the content based addressing found in these attention mechanisms. In particular for a NTM, at each timestep (t), for each read and write head the controller outputs a set of parameters: kt, βt ≥ 0, gt ∈ [0, 1], st (s.t. P k st(k) = 1 and ∀k st(k) ≥ 0) and γt ≥ 1 which are used to compute the weighting wt over the N memory locations in the memory matrix Mt as follows:
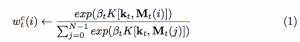
wc t allows for content based addressing where kt represents a lookup key into memory and K is some similarity measure such as cosine similarity:

Through a series of operations, Neural Turing Machines also enable iteration from current or previously computed memory weights as follows:

where (3) enables the network to choose whether to use the current content-based weights or the previous weight vector, (4) enables iteration through memory by convolving the current weighting by a 1-D convolutional shift kernel and (5) corrects for any blurring occurring as a result of the convolution operation. The vector rt read by a particular read head at timestep t is computed as:

Each write head modifies the memory matrix at timestep t by outputting additional erase (et) and add (at) vectors:

Equations (1) to (8) define how addresses are computed and used to read and write from memory in a Neural Turing Machine, but many implementation details of an NTM are open to choice. In particular the choice of the similarity measure K, the initial weightings w0 for all read and write heads, the initial state of the memory matrix M0, the choice of non-linearity to apply to the parameters outputted by each read and write head and the initial read vector r0 are all undefined in a NTM’s specification. While any choices for these satisfying the constraints on the parameters outputted by the controller would be a valid NTM, in practice these choices have a significant effect on the ability of a NTM to learn.
3 Our Implementation
Memory contents initialization – We hypothesize that how the memory contents of a Neural Turing Machineare initialized may be a defining factor in the success of a Neural Turing Machine implementation. We compare the three memory contents initialization schemes that we identified in open source implementations of NTMs. In particular, we compare constant initialization where all memory locations are initialized to 10−6 , learned initialization where we backpropagate through initialization and random initialization where each memory location is initialized to a value drawn from a truncated Normal distribution with mean 0 and standard deviation 0.5. We note that five of the seven implementations we identified randomly initialize the NTM’s memory contents. We also identified an implementation which initialized memory contents to a small constant value and an implementation where the memory initialization was learned.
Constant initialization has the advantage of requiring no additional parameters and providing a stable known memory initialization during inference. Learned initialization has the potential advantage of learning an initialization that would enable complex non-linear addressing schemes [6] while also providing stable initialization after training. This comes at the cost of N ∗ W extra parameters. Random initialization has the potential advantage of acting as a regularizer, but it is possible that during inference memory contents may be in a space not encountered during training.
Other parameter initialization – Instead of initializing the previously read vectors r0 and address weights w0 to bias values as per [4] we backpropagate through their initialization and thus initialize them to a learned bias vector. We argue that this initialization scheme provides sufficient generality for tasks that require more flexible initialization with little cost in extra parameters (the number of additional parameters is W ∗ Hr + N ∗ (Hr + Hw) where Hr is the number of read heads and Hw is the number of write heads). For example, if a Neural Turing Machinewith multiple write heads wishes to write to different memory locations at timestep 1 using location based addressing then w0 must be initialized differently for each write head. Having to hard code this for each task is an added burden on the engineer, particularly when the need for such addressing may not be known a priori for a given task, thus we allow the network to learn this initialization.
Similarity measure – For K, we follow [4] in using cosine similarity (2) which scales the dot product into the fixed range [−1, 1].
Controller inputs – At each timestep the controller is fed the concatenation of the input coming externally into the NTM xt and the previously read vectors rt−1 from all of the read heads of the NTM. We note that such a setup has achieved performance gains for attentional encoder-decoders in neural machine translation [9].
Parameter non-linearities – Similarly to a LSTM we force the contents of the memory matrix to be in the range [−1, 1], by applying the tanh function to the outputs of the controller corresponding to kt and at while we apply the sigmoid function to the corresponding erase vector et. We apply the function softplus(x) ← log(exp(x) + 1) to satisfy the constraint βt ≥ 0. We apply the logistic sigmoid function to satisfy the constraint gt ∈ [0, 1]. In order to make the convolutional shift vector st a valid probability distribution we apply the softmax function. In order to satisfy γt ≥ 1 we first apply the softplus function and then add 1.
4 Methodology
4.1 Tasks
We test our Neural Turing Machine implementation on three of the five artificial sequence learning tasks described in the original NTM paper [4].
Copy – for the Copy task, the network is fed a sequence of random bit vectors followed by an end of sequence marker. The network must then output the input sequence. This requires the network to store the input sequence and then read it back from memory. In our experiments, we train and test our networks on 8-bit random vectors with sequences of length sampled uniformly from [1, 20].
Repeat Copy – similarly to the Copy task, with Repeat Copy the network is fed an input sequence of random bit vectors. Unlike the Copy task, this is followed by a scalar that indicates how many times the network should repeat the input sequence in its output sequence. We train and test our networks on 8-bit random vectors with sequences of length sampled uniformly from [1, 10] and number of repeats also sampled uniformly from [1, 10].
Associative Recall – Associative Recall is also a sequence learning problem with sequences consisting of random bit vectors. In this case the inputs are divided into items, with each item consisting of 3 x 6-dimensional vectors. After being fed a sequence of items and an end of sequence marker, the network is then fed a query item which is an item from the input sequence. The correct output is the next item in the input sequence after the query item. We train and test our networks on sequences with the number of items sampled uniformly from [2, 6].
4.2 Experiments
We first run a set of experiments to establish the best memory contents initialization scheme. We compare the constant, random and learned initialization schemes on the above three tasks. We demonstrate below (Sec. 5) that the best such scheme is the constant initialization scheme. We then compare the Neural Turing Machine implementation described above (Sec. 3) under the constant initialization scheme to two other architectures on the Copy, Repeat Copy and Associative Recall tasks. We follow the NTM authors [4] in comparing our NTM implementation to a LSTM network.
As no official Neural Turing Machine implementation has been made open source, as a further benchmark, we compare our NTM implementation to the official implementation of a Differentiable Neural Computer (DNC) [5], a successor to the Neural Turing Machine. This provides a guide as to how a stable MANN implementation performs on the above tasks. In all of our experiments for each network we run training 10 times from different random initializations. To measure the learning speed, every 200 steps during training we evaluate the network on a validation set of 640 examples with the same distribution as the training set.
For all tasks the MANNs had 1 read and 1 write head, with an external memory unit of size 128 X 20 and a LSTM controller with 100 units. The controller outputs were clipped elementwise to the range (−20, 20). The LSTM networks were all a stack of 3 X 256 units. All networks were trained with the Adam optimizer [8] with learning rate 0.001 and on the backward pass gradients were clipped to a maximum gradient norm of 50 as described in [10].
5 Results
5.1 Memory Initialization Comparison
We hypothesized that how the memory contents of a NTM were initialized would be a key factor in a successful NTM implementation. We compare the three memory initialization schemes we identified in open source NTM implementations. We then use the best identified memory contents initialization scheme as the default for our NTM implementation.
Copy – Our NTM initialized according the constant initialization scheme converges to near zero error approximately 3.5 times faster than the learned initialization scheme, while the random initialization scheme fails to solve the Copy task in the allotted time (Fig. 1). The learning curves suggest that initializing the memory contents to small constant values offers a substantial speed-up in convergence over the other two memory initialization schemes for the Copy task.
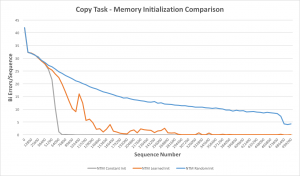
Fig. 1. Copy task memory initialization comparison – learning curves. Median error on 10 training runs (each) for a NTM initialized according to the constant, learned and random initialization schemes.
Repeat Copy – A NTM initialized according the constant initialization scheme converges to near zero error approximately 1.43 times faster than the learned initialization scheme and 1.35 times faster than the random initialization scheme (Fig. 2). The relative speed of convergence between learned and Implementing Neural Turing Machines 7 random initialization is reversed as compared with the Copy task, but again the constant initialization scheme demonstrates substantially faster learning than either alternative.

Fig. 2. Repeat Copy task memory initialization comparison – learning curves. Median error on 10 training runs (each) for a NTM initialized according to the constant, learned and random initialization schemes.
Associative Recall – A Neural Turing Machine initialized according to the constant initialization scheme converges to near zero error approximately 1.15 times faster than the learned initialization scheme and 5.3 times faster than the random initialization scheme (Fig. 3).
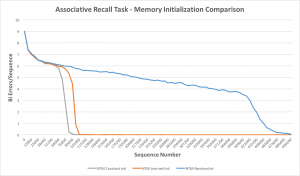
Fig. 3. Associative Recall task memory initialization comparison – learning curves. Median error on 10 training runs (each) for a NTM initialized according to the constant, learned and random initialization schemes.
The constant initialization scheme demonstrates fastest convergence to near zero error on all three tasks. We conclude that initializing the memory contents of a NTM to small constant values results in faster learning than backpropagating through memory contents initialization or randomly initializing memory contents. Thus, we use the constant initialization scheme as the default scheme for our NTM implementation.
5.2 Architecture Comparison
Now that we have established the best memory contents initialization scheme is constant initialization we wish to test whether our Neural Turing Machine implementation using this scheme is stable and has similar speed of learning and generalization ability as claimed in the original NTM paper. We compare the performance of our NTM to a LSTM and a DNC on the same three tasks as for our memory contents initialization experiments.
Copy – Our Neural Turing Machine implementation converges to zero error in a number of steps comparable to the best published results on this task [4] (Fig. 4). Our NTM converges to zero error 1.2 times slower than the DNC and as expected both MANNs learn substantially faster (4-5 times) than a LSTM.

Fig. 4. Copy task architecture comparison – learning curves. Median error on 10 training runs (each) for a DNC, NTM and LSTM.
Repeat Copy – As per [4], we also find that the LSTM performs better relative to the MANNs on Repeat Copy compared to the Copy task, converging only 1.44 times slower than a NTM, perhaps due to the shorter input sequences involved (Fig. 5). While both the DNC and the NTM demonstrate slow learning during the first third of training both architectures then rapidly fall to near zero error before the LSTM. Despite the NTM learning slower than the DNC during early training, the DNC converges to near zero error just 1.06 times faster than the NTM.

Fig. 5. Repeat Copy task architecture comparison – learning curves. Median error on 10 training runs (each) for a DNC, NTM and LSTM.
Associative Recall – Our NTM implementation converges to zero error in a number of steps almost identical to the best published results on this task [4] and at the same rate as the DNC (Fig. 6). The LSTM network fails to solve the task in the time provided.

Fig. 6. Associative Recall task architecture comparison – learning curves. Median error on 10 training runs (each) for a DNC, NTM and LSTM.
Our Neural Turing Machine implementation learns to solve all three of the five tasks proposed in the original NTM paper [4] that we tested. Our implementation’s speed to convergence and relative performance to LSTMs is similar to the results reported in the NTM paper. Speed to convergence for our NTM is only slightly slower than a DNC – another MANN. We conclude that our NTM implementation can be used reliably in new applications of MANNs.
6 Summary
Neural Turing Machines are an exciting new neural network architecture that achieve impressive performance on a range of artificial tasks. But the specification of a NTM leaves many free choices to the implementor and no source code is provided that makes these choices and replicates the published NTM results. In practice the choices left to the implementor have a significant impact on the ability of a NTM to learn. We observe great diversity in how these choices are made amongst open source efforts to implement a NTM, many of which fail to replicate these published results.
We have demonstrated that the choice of memory contents initialization scheme is crucial to successfully implementing a NTM. We conclude from the learning curves on three sequential learning tasks that learning is fastest under the constant initialization scheme. We note that the random initialization scheme which was used in five of the seven identified open source implementations was the slowest to converge on two of the three tasks and the second slowest on the Repeat Copy task.
We have made our Neural Turing Machine implementation with the constant initialization scheme open source. Our implementation has learned the Copy, Repeat Copy and Associative Recall tasks at a comparable speed to previously published results and the official implementation of a DNC. Training of our NTM is stable and does not suffer from problems such as gradients becoming NaN reported in other implementations. Our implementation can be reliably used for new applications of NTMs. Additionally, further research on NTMs will be aided by a stable, performant open source NTM implementation.
Acknowledgements This publication emanated from research conducted with the financial support of Science Foundation Ireland (SFI) under Grant Number 13/RC/2106.
References
1. Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014)
2. Graves, A., Liwicki, M., Fernndez, S., Bertolami, R., Bunke, H., Schmidhuber, J.: A novel connectionist system for unconstrained handwriting recognition. IEEE transactions on pattern analysis and machine intelligence 31(5), 855–868 (2009)
3. Graves, A., Mohamed, A.r., Hinton, G.: Speech recognition with deep recurrent neural networks. In: Acoustics, speech and signal processing (icassp), 2013 ieee international conference on. pp. 6645–6649. IEEE
4. Graves, A., Wayne, G., Danihelka, I.: Neural turing machines. arXiv preprint arXiv:1410.5401 (2014)
5. Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., Grabska-Barwiska, A., Colmenarejo, S.G., Grefenstette, E., Ramalho, T., Agapiou, J.: Hybrid computing using a neural network with dynamic external memory. Nature 538(7626), 471 (2016)
6. Gulcehre, C., Chandar, S., Cho, K., Bengio, Y.: Dynamic neural turing machine with soft and hard addressing schemes. arXiv preprint arXiv:1607.00036 (2016)
7. Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural computation 9(8), 1735–1780 (1997)
8. Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
9. Luong, T., Pham, H., Manning, C.D.: Effective approaches to attention-based neural machine translation. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. pp. 1412–1421
10. Pascanu, R., Mikolov, T., Bengio, Y.: On the difficulty of training recurrent neural networks. In: International Conference on Machine Learning. pp. 1310–1318 (2013)
11. Sukhbaatar, S., Weston, J., Fergus, R.: End-to-end memory networks. In: Advances in neural information processing systems. pp. 2440–2448
12. Wu, Y., Schuster, M., Chen, Z., Le, Q.V., Norouzi, M., Macherey, W., Krikun, M., Cao, Y., Gao, Q., Macherey, K.: Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144 (2016)


0 Comments