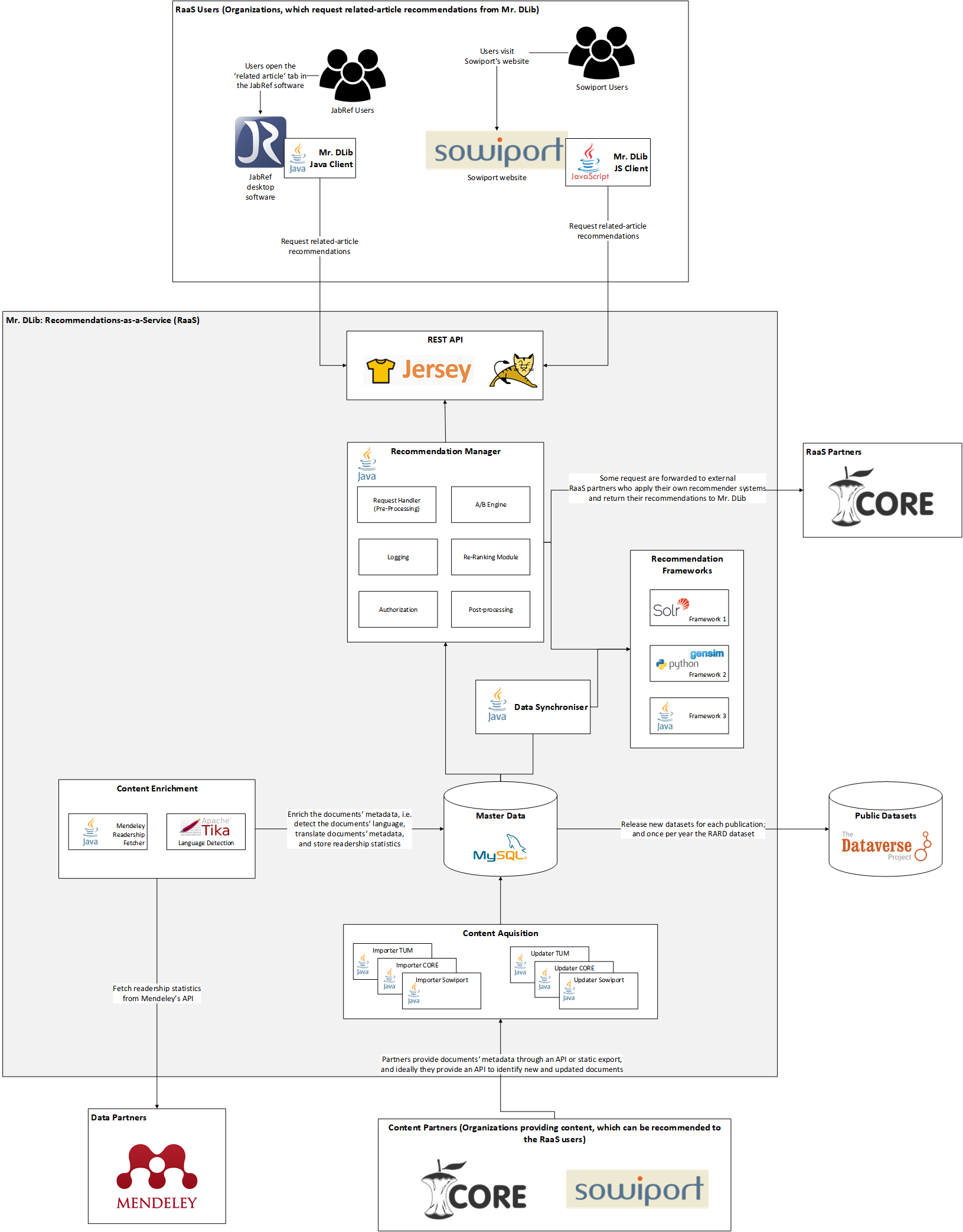
Mr. DLib: Recommender-System as-a-Service
We have integrated several new recommendation algorithms into Mr. DLib. Some recommendation algorithms are only ought as baselines for our researchers, others hopefully will further increase the effectiveness of Mr. DLib.
Overall, Mr. DLib now uses the following recommendation algorithms in its recommender system:
Random Recommendations
The approach recommendation randomly picks the set of documents to recommend. We experiment with this approach by randomly choosing to apply a language filter 50% of the time. With the language filter, the recommended documents share the same language as the input document.
Lucene’s More Like This
This is one of the most commonly applied recommendation aproaches for content-based filtering. The approach concatenates and tokenizes a document’s title, abstract, keywords, and journal name using Apache Lucene’s out-of-the-box Standard Tokenizer. The tokens are then indexed, and recommendations are made using Lucene’s More Like This feature.
Stereotype Recommendations
Stereotyping uses a primitive user modeling strategy with fixed recommendation classes. Users are classified, or stereotyped into generic groups and each group is assigned the same set of recommendations that we hand-picked. For Mr. DLib’s recommender system, we assume that all users are researchers or students; hence, we hand-picked a number of documents relating to academic writing, peer review, and research methods.
Most Popular
This recommendation approach recommends the most viewed and exported documents of the past months.
Keyphrase Content-Based Filtering
This is an advanced approach which is an adaptation of the Key-phrase based approach used by Ferrera et al. (2011) Whereas the original approach requires the full text of a paper to build acceptable key-phrases,
we adapted the approach to do so even with only the title of the paper as input.
Ferrara, F., Pudota, N., and Tasso, C. A Keyphrase-Based Paper Recommender System. Springer Berlin Heidelberg, Berlin, Heidelberg, 2011, pp. 14–25.
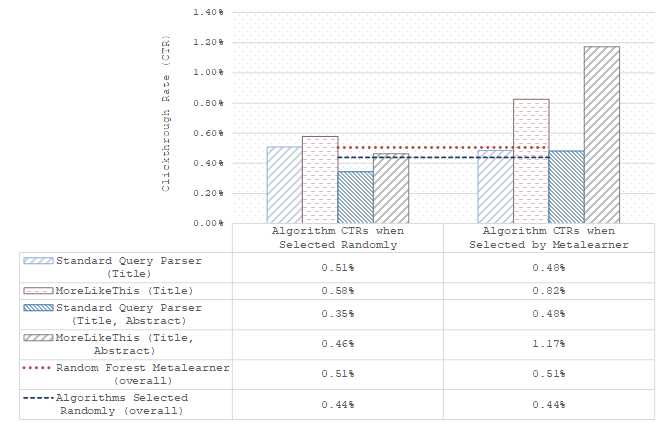

0 Comments