Finally, after releasing the alpha and beta, today we release Docear 1.1 stable. If you have tried already one of the previous versions, there is not much news. Otherwise, read on.
Thanks to all the generous donors, our student Christoph could work on an improved PDF metadata retrieval for Docear. The new Docear 1.1 is able to extract the title of a PDF and fetch metadata from Google Scholar for that title. To do so, select a PDF in your mind-map and chose “Create or Update reference”, …
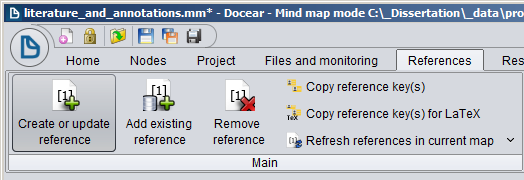
… and the following new dialog appears. The dialog shows the file name of your PDF file, and the extracted title. In the background, the extracted title is sent to Google Scholar and metadata for the first two search results are shown in the dialog. If the title was extracted incorrectly, you can manually correct it. You may also chose to use the PDF’s file name for the search. For instance, when you named your PDF already according to the title, select the radio button with the file name, and the file name is sent as search query to Google Scholar (you may also manually correct the file name before it’s sent to Google Scholar). Of course, all other options you already know are still available, such as creating a blank entry, or importing the XMP data of PDFs. Btw. Docear remembers your choice, i.e. when you select to create a blank entry, the option will be pre-selected when open that dialog the next time. It might happen, that your IP will be blocked by Google Scholar when you use the service too frequently. If this happens, a captcha should appear, and after solving it, you should be able to proceed. We did not yet test this thoroughly. Please let us know your experiences.

The precision of our metadata tool depends on two factors, A) the precision of the title extraction and B) the coverage of Google Scholar. According to a recent experiment, title extraction of our tool is around 70%. However, the final result very much depends on the format of your research articles. In my research field (i.e. recommender systems), I would say that our tool extracts the title correctly for about 90% of the articles in my personal library. In addition, almost all articles that are relevant for my research are indexed by Google Scholar (i would estimate, more than 90%). This means, for around 80% of my PDFs the correct metadata is retrieved fully automatically. Given that I provide the title manually, for even more than 90% the metadata may be retrieved. Please let us know your experience (and your research field).
The functionality is directly integrated into Docear’s desktop software. This means, you do not depend any more on Docear’s Web Services, which, admittedly, was not always the most reliable service. In addition, the entire source code is open-source, and other projects are welcome to use it for their own purposes. If Docear’s licence (GPL) is not suitable for your project, let us know. We have no problem to additionally release the code under another open source licence such as Apache or whatsoever.
Apart from the metadata retrieval we have improved how Docear handles BibTeX files from Mendeley and Zotero. Both use other BibTeX dialects than JabRef (our integrated reference manager). Zotero for instance does not escape colons and semicolons in file descriptions or file names. But these characters carry a special meaning in BibTeX file fields which makes these fields very hard to read automatically. Other differences are how absolute paths are stored, if backslash characters or hash characters are escaped, etc. We hope that Docear now deals better with these BibTeX files. We have also fixed an issue which could freeze Docear after converting a BibTeX file. Due to several problems we had to remove proxy support in the current version of Docear. We know, this is really annoying and we hope to be able to implement a better version soon.
Here are all changes since Docear 1.03
New features include:
- New PDF metadata extraction based on Google Scholar
Enhancements include:
- “Show in reference manager” works with multiple PDF files
- Prevent Docear from opening new BibTeX files through Drag&Drop
- Prevent from “flickering” caused by annotation updater on a lot of nodes
- “Delete file from disk” is more distinct to select
- Recommendation Rating more obtrusive
Bugfixes include:
- Broken BibTeX file freezes Docear on startup
- “Remove line breaks from annotation” did not work
- PDF metadata extraction freezes Docear for a PDF file
- Docear installer could not find installed JRE, while the All-OS version can
- Special PDF file caused refresh abort
- Copy reference key did not work when a non-reference node was selected first
- NPE after changing year attribute on mind map node
- NPE caused by AnnotationExtractor
- Caught exception thrown when Windows registry could not be read correctly
- MultiLineActionLabel link mark (underline) is not wrapped correctly
- Removing line breaks by default did not work
Some additional tickets we worked on during the implementation of the metadata extraction:
- Metadata extraction on PDF with multiple nodes
- Make inactive fields more consistent in metadata retrieval wizard
- Limit title to use only one line in metadata extraction dialog
- Show file extension in metadata extraction dialog
- Search external sources only when radio button is selected
- ‘Esc’ key executes ‘cancel’ button
- Change some strings im metadata extraction dialog
- Drag&Drop for already referenced PDFs is not working
- Request metadata from Google Scholar
- Improved PDF Metadata Extraction Dialog
- Components sometimes leave the visible area of the wizard


12 Comments
Trevor · 9th February 2015 at 18:42
I am having this same problem, and deleting the user settings (including the Google Scholar cookie) does nothing; I continue to see captcha request after captcha request, whether my input to the captcha is correct or incorrect.
What should I do?
Heba · 5th December 2014 at 22:43
I have similar problem with Captcha requests. By entering the correct word in the box for several time, it does not work. I have tried deleting the settings files as well, does not work either
Marc · 9th September 2014 at 10:02
Thank you.
Tried back at my flat which has a broadband connection, after deleting the settings files managed to get everything working again. But returning to the Uni department this morning the functionality is not working.
I can sort of work around this by copying the bibtex information from google scholar in a web browser. Pasting it in to the reference manager and linking the node to the reference. But this is of course a few extra steps.
Marc · 8th September 2014 at 15:28
Having similar problems with Captcha requests. Entering the correct word in the dialog does not work, neither does deleting the settings files. Running Mac OS X 10.9.4 and sitting behind a static uni IP
Joeran [Docear] · 8th September 2014 at 18:30
we will look into this…
Bernd · 31st August 2014 at 11:45
The an alyses of PDF to obtain reference data on title, authors etc. works very nicely and wrong guess can easily be corrrected by adding a number of right search terms separated by comma. But after havind dons this for 14 references and allowing about 15 answers for each, I am blocked permanently by multiple and never ending captcha requests (I assume from google scholar) and so I cannot use the system anymore to identify other references. Too bad. I will probably hafe to lock for another solution.
Joeran [Docear] · 31st August 2014 at 12:55
several users reported similar problems in the past couple of days. could you please try to delete your docear settings http://www.docear.org/support/user-manual/#ClearDelete_Settings and let me know if this solves the problem? it would also help us if you could tell us your operating system and whether you are working at a university with a static IP, or from home with a dynamic IP
Jonathan Cole · 29th July 2014 at 12:41
I’m new to Docear and was hoping to try it out. Unfortunately I just found this post where you have said proxy support has been removed.
Is there a timeframe for when proxy support might come back?
Joeran [Docear] · 30th July 2014 at 14:08
we have currently so much to do that I don’t know when we will bring back the proxy support, sorry.
kartoffelsalat · 16th July 2014 at 10:51
Thanks for your great work, the PDF metadata retrieval works almost seamlessly.
Nevertheless, I’m facing difficulties with PDFs from Elsevier, Journal of Memory and Language (http://www.sciencedirect.com/science/journal/0749596X ). It might be some other journals in this format, too. Docear’s metadata retrieval retrieves as title the Journal title and not the paper title.
Joeran [Docear] · 21st July 2014 at 10:37
Docear recognizes the largest font on the first page as title. Unfortunately, many Elsevier Journals have their journal title as largest font. We are aware of this problem but I am afraid we won’t be able to fix this soon. However, the pdf title extraction is open source. If anybody out there want to improve it: go ahead! 🙂
Michael Strack · 9th July 2014 at 04:11
Glad to hear about the stable release. I’m looking forward to getting around to trying Docear in the next few months – I’m currently using various programs for each separate task of managing and annotating PDFs, synthesising knowledge into larger paragraphs of notes, arranging them into concept maps, share them with colleagues and the public etc. I think an integrated software suite is an exciting prospect – good luck, and I’ll let you know how I get along!