One of Docear’s most unique feature is its “single-section” user-interface, which allows a highly effective organization of your PDFs, references, and notes. When you want to look-up some information you browse through your data, and usually you should be able to find what you are looking for quite fast. However, sometimes browsing your data is not ideal and you want to search over the papers’ full-text or meta data (title, author, …), or you want to use (social) tags to classify your papers.
Unfortunately, there is one problem about tags: they are one-dimensional. Imagine, you wanted to do a literature survey about recommender systems, and you have dozens of papers about this topic. Some of the papers’ authors evaluated their recommender system with user studies, some with offline experiments, and some with online experiments. The user studies were conducted with with different amounts of participants e.g. one study was conducted with 20 participants, one with 43, and one with 68. With social tags it would be difficult to represent this information. Of course, you could easily add the tag “recommender system” to each of your papers, but how about reflecting the evaluation type? Would you want to create different tags for each evaluation type, i.e. evaluation_user-study, evaluation_offline, evaluation_online? You might do this, but in situations with more than three options this approach would become confusing. You definitely run into a problem when you want to store the amount of study participants via social tags. This simply wouldn’t be possible except maybe you would create tags like no_of_participants_1-10, no_of_participants_11-50, etc.
What you would want to have are “2-dimensional” tags, i.e. one dimension for adding e.g. the tag “evaluation_type” to a paper and one dimension for specifying which evaluation type it is (e.g. “offline evaluation”). In Docear, there are two-dimensional tags, i.e. attribute-value pairs, and these attributes give you much more power than social tags. Here is, how it works:
Creating attributes
Let’s assume, you have a number of PDFs about recommender systems and these PDFs are being organized in your “Literature & Annotations” mind map.

To add an attribute, select “Edit attribute in-line” from the Resources ribbon, or press ALT+F9. An empty attribute field will appear, in which…

… you can freely define an attribute name (e.g. “evaluation_type”) and attribute value (e.g. “offline”). These “2-dimensional” attributes will later allow a more specific search than with classic tags. For instance, you will be able so easily filter all papers that were evaluated with an offline evaluation.

To create an additional attribute, just select the entry in the menu again or press the TAB key on your keyboard. This way, you can easily classify your entire literature which should look like this, when you are done.

If you think the attributes take too much space on your screen, you can hide them by selecting “Hide All Attributes” in the “View” ribbon.

If you want, you can also add “tags” to a paper. Just define an attribute with the name “tags” and add all relevant tags as keyword list, divided by comma.

Docear’s search function
To search for a specific paper, press CTRL+G on you keyboard, or select “Search” in the “Search and filter” ribbon. In contrast to many other reference managers, Docear does not only provide a normal text search over all information available. You can specify that a paper must (not) have a certain attribute, an attribute must equal a given string, contain a given string, or is larger/smaller than a given number. You may even use regular expressions to define the search criteria. Of course, the search works not only for attributes but you can also search for node-text, etc. What Docear does not (yet) provide is a full-text search over your PDFs, or a search over multiple mind maps. BTW. Docear also stores the papers’ bibliographic data as attributes. This means with the search function you could also search for papers being published e.g. in 2004 or for papers whose author list contains the name “Smith”.

Docear’s filtering function
Docear’s filter function gives you a lot of control about which information is shown in your mind maps. Filtering works as described in the following paragraphs.
Select “Compose filter” (1) to open the filter dialog. You can define where to apply the filter to (node text, attributes, hyperlinks, …), a filter condition (equals, contains, larger than, …) and the filter criterion itself (2). By clicking the “Add” button (3) the filter is added to the list of available filters (4). Then you can select a filter from the list and press OK or Apply (OK applies the filter and closes the dialog; Apply applies the filter and keeps the dialog open) (5).

Once you apply a filter, all nodes that are not matching the filter criteria disappear, and only those nodes matching the criteria remain. In the example below, only those nodes matching “evaluation_type=user” remain.
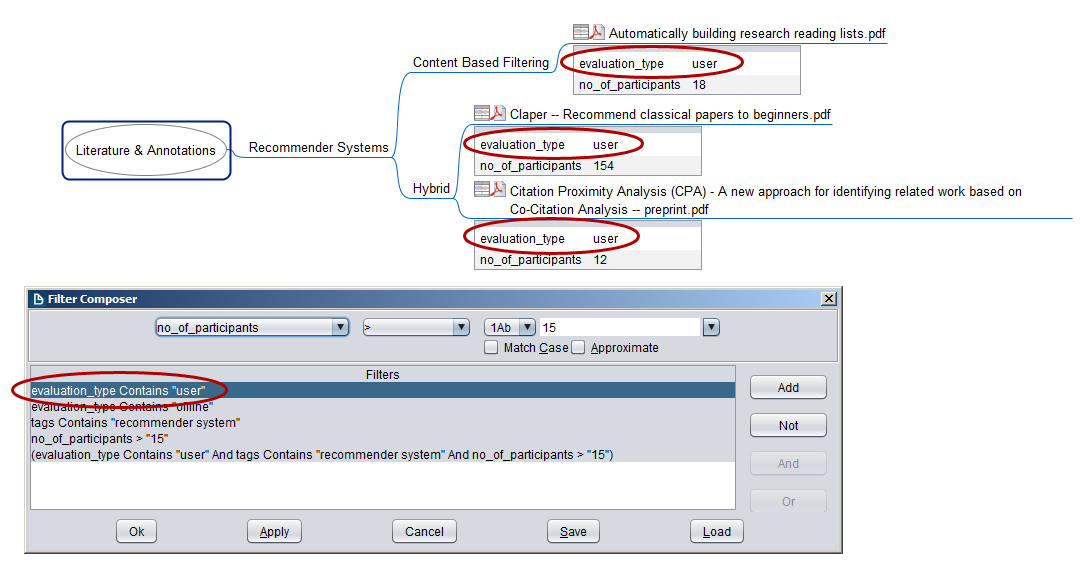
If you want your filtered papers as a plain list, de-select the “Show ancestors” condition and all filter results appear as direct child nodes of the root node.

Finally, you can connect multiple filters with AND, OR, and NOT conditions. To do so, select multiple filters with the mouse and keep the CTRL key on your keyboard pressed while selecting the filters. Then select e.g. “AND” in the dialog, and a new filter is added to the list.
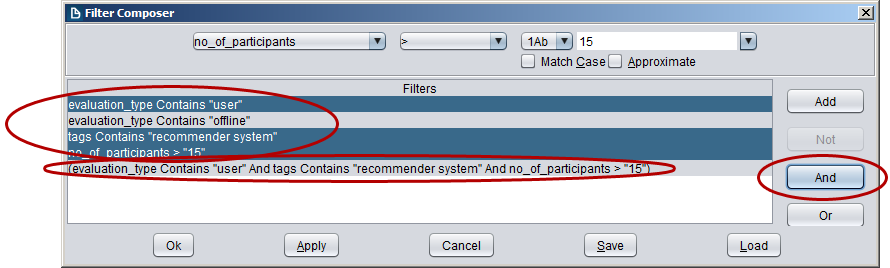
To the best of our knowledge, Docear’s filter function is the most comprehensive and powerful function to search, respectively filter, your literature. Having attributes gives you a far more options for classifying your literature, compared to classic search or social tagging. We know this from our own experience. For a recent literature survey about research paper recommender systems, we had to classify almost 100 papers and analyze how many systems were evaluated with offline, online or user studies, how many participants the studies had, which evaluation metrics were used, which baselines the systems were compared to, and so on and so forth. Creating these statistics with Docear was a piece of cake (once we did read all the papers which, of course, took us weeks). With classic tags this would have been far more difficult (if not to say impossible).
However, we know that the filter function is not the most user-friendly function and we are very interested to hear if and how you are using it, and how we could improve it. Please post your feedback directly as comment to this post!



11 Comments
james · 12th September 2021 at 09:30
This is no different to regular facet filters, been around 20 years.
Joeran Beel · 12th September 2021 at 12:32
And does any other reference management software support “regular faces filters” (that can be applied not only to PDF files but also passages within PDFs, i.e. highlighted sentences, etc)?
MARCELA DE MARCO SOBRAL · 8th July 2018 at 03:57
Ola, COmo eu faço para utilizar outro sistema de citação o ABNTEX2? EU encontrei o arquivo mas não consegui instalar no DOCEAR
Kurt · 22nd November 2016 at 21:27
You used a list of tags as an example of an attribute. Is there a way to see a list of all the tags used (rather than a list of all the tag strings – i.e. not a list of all the comma-separated strings but a list of all the elements -> tag1, tag2, tag3 rather than (tag1, tag2), (tag1, tag3)…)
I hope this is a clear question. 🙂
starstuff · 16th September 2014 at 07:55
I think it would be better if we can have a dedicated button for filter – Quick Filter – and use checkmarks [check] to select/add/combine filters, this is similar to libreoffice calc and excel filter.
wgcitgkaka · 26th May 2014 at 09:26
what does the 1ab mean in the search dialog?
Joeran [Docear] · 26th May 2014 at 09:40
The “1Ab” is about how the “<" is calculated. To be honest, this function was implemented by the Freeplane team, as such I don't know exactly what the differences are.
Divakar · 3rd September 2015 at 06:11
My guess is it specifies the sort order: numerals followed by capital alphabets followed by small letters.
jzadra · 29th January 2014 at 11:21
It would be great if docear could add a “keyword” attribute that is populated by the author supplied keywords harvested from the keywords provided in the pdf (via doc inspector) or the doi retrieval.
Joeran [Docear] · 29th January 2014 at 18:40
that’s a great idea. would you mind, posting it here? http://docear.uservoice.com/forums/124375-docear-s-feature-wishlist
Rachel · 2nd December 2013 at 01:05
Thanks for this explanation, I hadn’t tried any of these features but am thinking they would be well worth the time.