I am pleased to share that our bachelor student, Leonie Winter, has successfully completed her thesis (arXiv) at my chair — and she did an excellent job. Her work follows up on our earlier study on pruning in recommender-system evaluations and pushes the discussion further in scope and clarity.
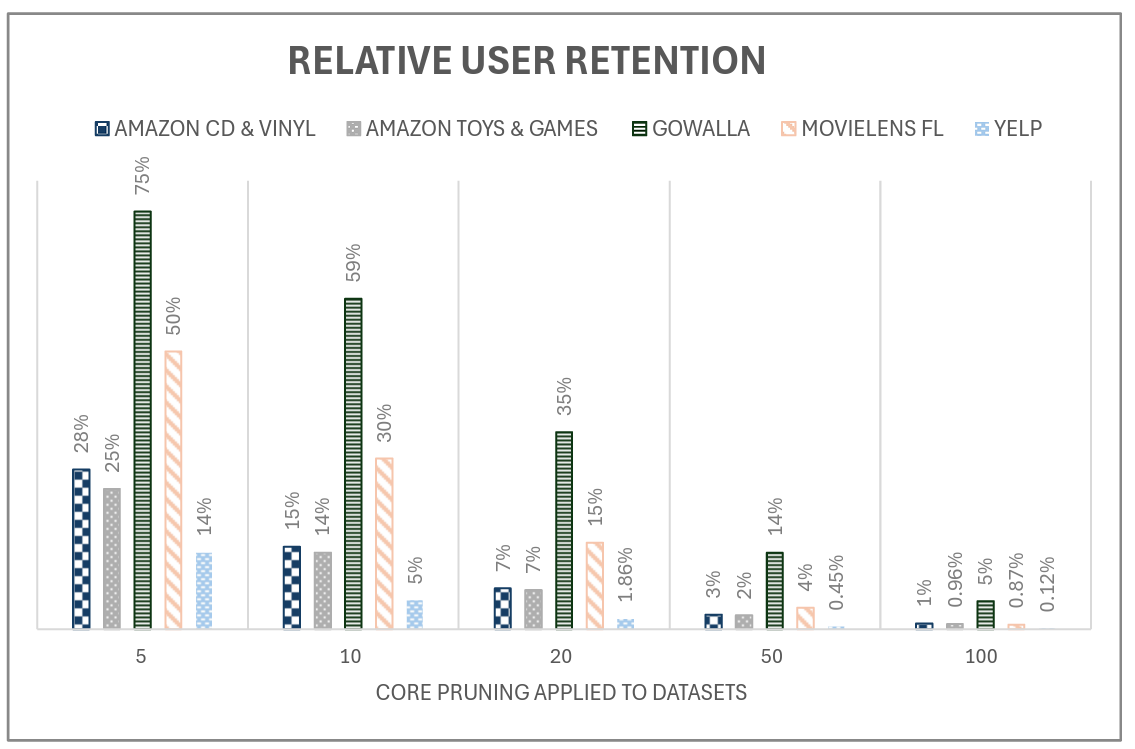
The thesis asks a simple question with broad implications: what does dataset pruning actually do to our evaluations of recommender systems? Leonie shows that even modest “n-core” pruning removes a large share of users from common benchmark datasets—often leaving only a small minority at typical thresholds—so the population we evaluate on no longer reflects real use. For instance, at 20-core many datasets retain 15% or fewer of their original users; on Yelp, only 0.12% remain at 100-core.
She then demonstrates why this matters. When both training and testing are performed on pruned data, scores tend to look better; when the exact same models are tested on unpruned data, the apparent gains largely disappear. In other words, pruning the test set inflates results and can reshuffle algorithm rankings, whereas introducing unpruned test users (including low-activity “cold-start” users) removes that inflation. This confirms and extends our prior findings.
A second clear result is comparative: on unpruned tests, contemporary models achieve higher absolute accuracy than traditional methods, yet all methods degrade as pruning becomes more severe. Notably, SimpleX produced the highest observed scores when trained on pruned data and tested on unpruned data, but its performance still fell as pruning intensified—evidence that aggressive pruning harms generalisation rather than helping it.
The practical takeaway is straightforward. Use pruned datasets carefully and never as the only evidence; if compute is constrained, train on pruned data but test on unpruned data, and always document preprocessing. These practices improve fairness, comparability, and external validity.
This is outstanding work for a bachelor thesis—methodically argued, impactful in its conclusions, and tightly aligned with how recommender-system evaluation is evolving. Anyone interested in the evolution of recommender evaluations should read it: https://arxiv.org/abs/2510.14704



0 Comments