I love Google Scholar, it’s an amazing search engine for academics, and I have done quite a bit of research on Google Scholar, including an analysis of Google Scholar’s ranking algorithm and the effect of citations on ranking, Google Scholar’s vulnerability against spam, and guidelines for ‘academic search engine optimization (ASEO)‘.
However, sometimes Google Scholar still leaves me puzzled and I wonder what the logic is behind Google Scholar’s indexing practice. For instance, yesterday, I realized some weird indexing for one of my recently published articles:
Beel, Joeran, Barry Smyth, and Andrew Collins. “RARD II: The 94 Million Related-Article Recommendation Dataset.” In Proceedings of the 1st Interdisciplinary Workshop on Algorithm Selection and Meta-Learning in Information Retrieval (AMIR), 39–55. CEUR-WS, 2019.
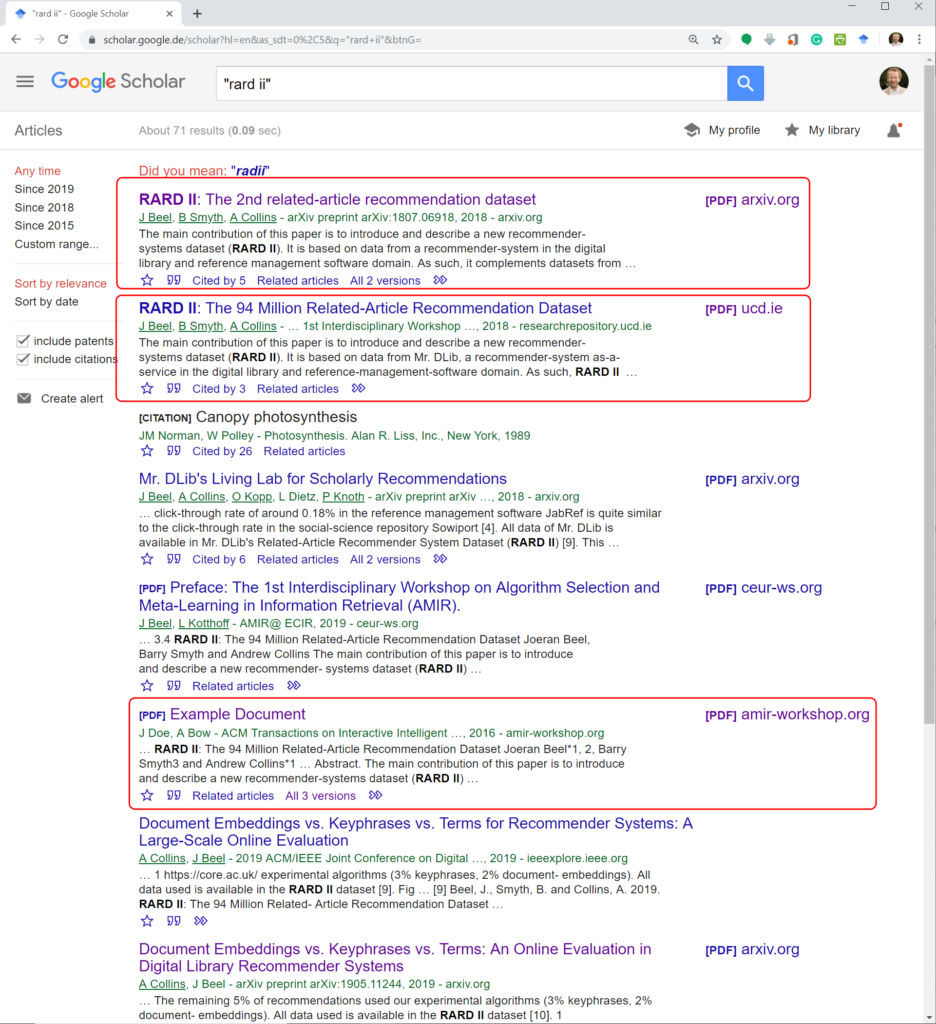
The problem is as follows, namely, the article is incorrectly indexed by Google Scholar. According to Google Scholar, the title of the document is “Example Document”, the authors are “J. Doe” and “A. Bow” and the paper was published in “ACM Transactions on Interactive Intelligent Systems” in “2016” (see below). So, in short, Google Scholar got it completely wrong.

I wondered how this could be. The article is in ‘normal’ PDF format with the title being the largest font on the front page (so, extraction and identification of the title directly from the PDF should be easy)…
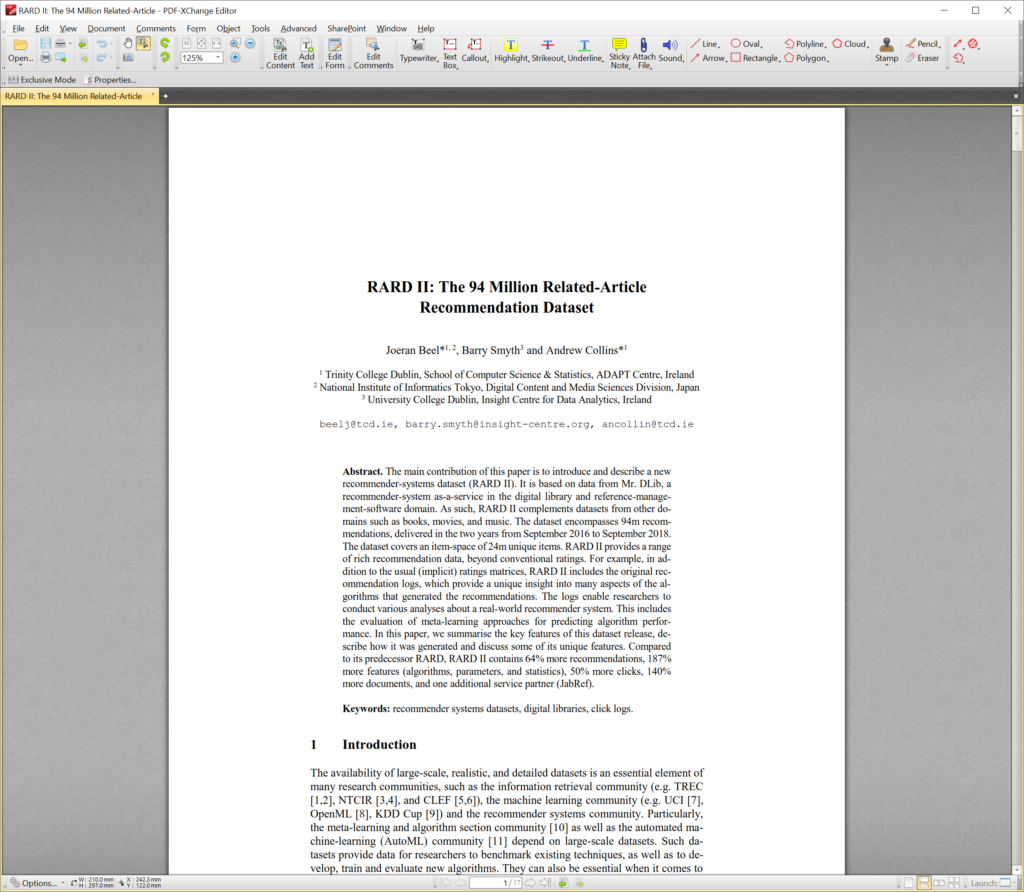
I had even added the meta-data to the PDF (well, I did a little mistake and saved only half of the title, but still the title of the metadata was not “Example Document”).

The data on the proceedings page was correct…
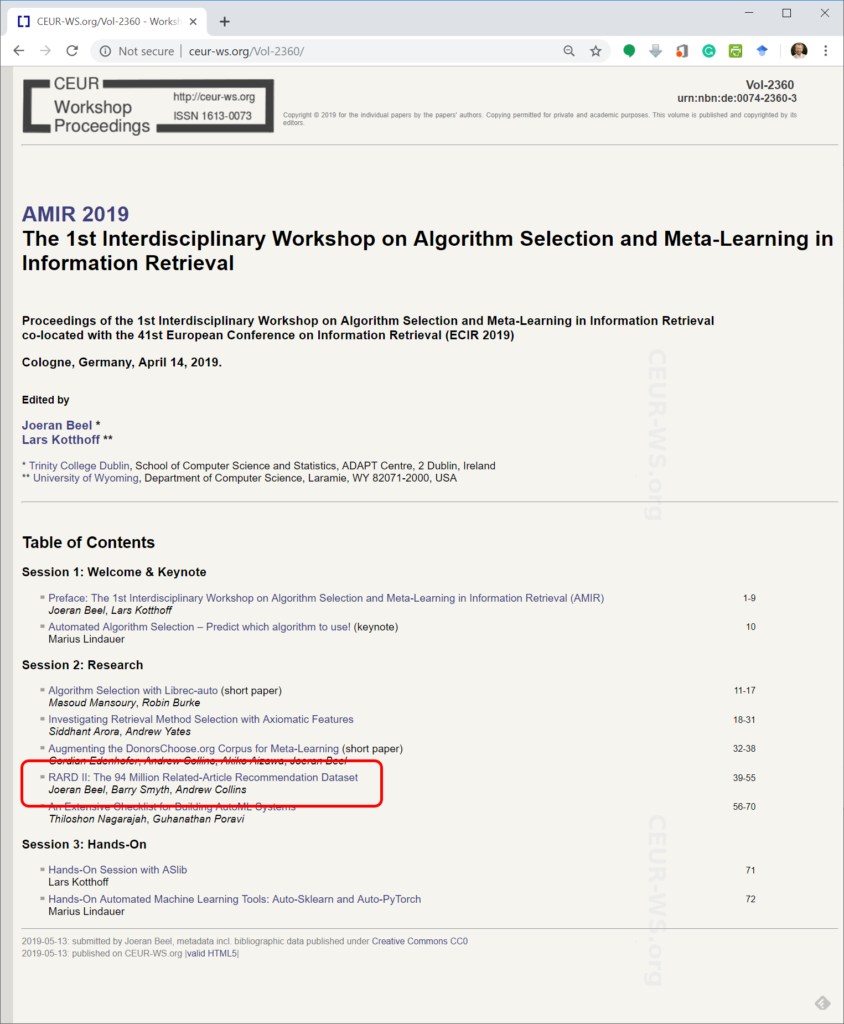
… and the data on the workshop page was correct.

Google Scholar had even correctly indexed a previously published preprint version of the article, though that preprint had a slightly different title but same authors and mostly the same content.

And, maybe most importantly, Google Scholar had indexed the article from the UCD Pre-Print repository with the 100% correct meta-data.

Yet, even though the correct article was already in Google Scholar’s system, Google Scholar decided to index the article again from the workshop web page, etc. with completely incorrect meta-data.
How could that be? Well, I searched for the string “Doe” in the PDF, and easily found the answer. Google had taken the incorrect meta-data — at least the title and authors — from a vector graphic that I had embedded in the article (see below).

The journal name (Transactions on Interactive Intelligent Systems) and the year (2016), however, did not occur in this vector graphic. The only place these strings occurred was in the reference list.

So, in summary, it seems that Google Scholar parsed the entire PDF and believed the meta-data of the current file was a mix of strings occurring a) in the middle of the document in a vector graphic (title and author) and b) in one of the entries in the reference list (Journal and Year). As a consequence, the article is indexed three times and may appear three times in the search results (I guess, having the arXiv preprint and final version being indexed separately makes some sense; having the “Example Document” indexed is obviously not ideal though).
0 Comments