
One month ago, we started a call for donation and asked our users for money so we could pay our student Christoph to improve Docear’s PDF metadata retrieval. We asked for 1800 Euros (~2500 US$) and today we achieved our goal. We would like to thank all donors who made this possible. We received dozens of donations, the highest being 250 Euros and a few others around 100 and 150 Euros. But however large your small your contribution was, be ensured that we highly appreciate it.
As of today, Christoph starts with his work. Cross your fingers that he will be able to finish as much tickets as possible. He will start with improving the dialog to retrieve metadata and implementing a function to request metadata from Google Scholar. This way, you won’t depend on Docear’s Web Service any more. You can follow the progress on GitHub, feel free to tell us all your ideas and wishes you have directly here in the Blog or on GitHub.
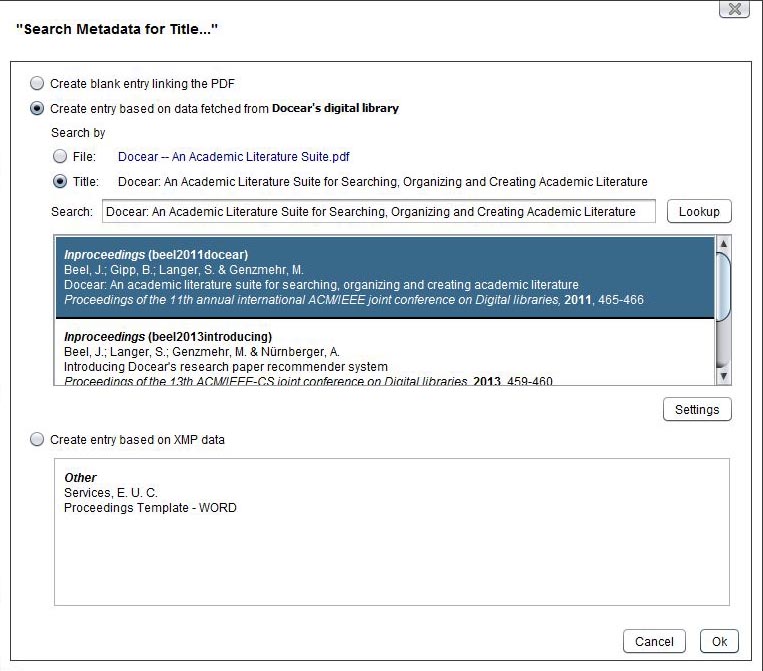
Update March 7: Here is a screenshot of the new dialog. It works already pretty well. When you want to create a new reference for a PDF, the title is extracted automatically and sent to Google Scholar. The first three matches of Google Scholar are shown and you can pick one. In case the title is not extracted correctly, you can alter the search string. Alternatively, you may choose to use the PDF’s file name as search string. The next step will be to add a option to answer Google Scholar’s captcha (when you query Google Scholar too often, Google bans your IP you unless you enter a captcha).

6 Comments
tedus · 13th October 2016 at 14:27
mal ein wenig ab vom Thema: mr.dlib ist ja soweit ich verstehe eine Artikel-Empfehlungs-Software.
Sowas gab es vor einer Zeit mal von Tobias Meier unter dem Namen recently (weitergen-blog: http://scienceblogs.de/weitergen/tag/recently/).
Die Umsetzung war sehr gut – und auch in der kurzen Zeit in der es sie gab recht populär (findet man einige Test drüber). Auch optisch war das ganze recht ansprechend.
Aus irgendeinem Grund (den ich vergessen habe) wurde das ganze aber eingestellt.
Da ich über den blog auch schon mal mit ihm geschrieben hab, kann ich nur anmerken, das Tobias ein sehr netter Zeitgenosse ist.
vielleicht könnt ihr ihn ja mal anschreiben und vielleicht Teile / Inspiration o.ä. von seiner leider eingestellten Software übernehmen. Fällt mir zumindestens ein, als ich euren Beitrag gelesen hab.
7h5 · 2nd July 2014 at 10:33
Did Christoph also manage to implement the renaming PDF functionality? And if so is that part of docear 1.1.0.1?
cheers and thanks for this wonderful software
Joeran [Docear] · 7th July 2014 at 14:17
no sorry, he only implemented the metadata retrieval from google scholar
Marc · 24th March 2014 at 11:38
Do you have any updates about the progress of the addon?
Joeran [Docear] · 24th March 2014 at 14:00
Our student Christoph is basically done with his work. In a few days we will release a preview version that has the new dialog and can retrieve metadata from Google Scholar.
Ben Nessib · 26th February 2014 at 11:32
Congratulations!