Tobias Vente, Lukas Wegmeth, Alan Said, and Joeran Beel. 2024. From Clicks to Carbon: The Ecological Costs of Recommender Systems. In 18th ACM Conference on Recommender Systems (RecSys ’24), October 14–18, 2024, Bari, Italy. ACM, New York, NY, USA, 11 pages. https://doi.org/10.1145/3640457.
Full pre-print as PDF: https://arxiv.org/abs/2408.08203
Abstract
As global warming soars, the need to assess the environmental impact of research is becoming increasingly urgent. Despite this, few recommender systems research papers address their environmental impact. In this study, we estimate the ecological impact of recommender systems research by reproducing typical experimental pipelines. Our analysis spans 79 full papers from the 2013 and 2023 ACM RecSys conferences, comparing traditional “good old fashioned AI” algorithms with modern deep learning algorithms. We designed and reproduced representative experimental pipelines for both years, measuring energy consumption with a hardware energy meter and converting it to CO2 equivalents. Our results show that the choice of hardware, algorithms, and datasets significantly impacts energy consumption and carbon footprint. In some instances, using energy-efficient hardware (Apple M1 instead of NVIDIA RTX 3090) lowers carbon emissions by as much as 90%, while achieving the same performance.
Experiments consume up to 1,444 times more energy depending on the dataset (DGCF on LastFM vs. Yelp) and 257 times more depending on the algorithm (MacridVAE vs. Popularity on Yelp). Combined, algorithm and dataset choices can lead to an energy consumption difference of up to factor 134,000 (Popularity on LastFM vs. DGCF on Yelp). Also, papers using deep learning algorithms emit approximately 42 times more CO2 equivalents than experiments using traditional algorithms. On average, a single deep learning-based paper generates 3,297 kilograms of CO2 equivalents — more than the carbon emissions of one person flying from New York City to Melbourne or the amount of CO2 one tree sequesters over 300 years.
Introduction
Carbon emissions play a pivotal role in global warming by driving the greenhouse effect that leads to rising temperatures and extreme weather events [21, 28, 37, 40, 45]. With the ambitious goal of the United Nations Framework Convention on Climate Change to cap the global warming temperature increase at 1.5 degrees Celsius1, reducing carbon emissions becomes crucial [21]. Therefore, significant reductions in carbon emissions are urgently needed to meet the temperature target and mitigate the climate impact [21, 45, 57].
Concurrently, computationally heavy algorithms have become the norm for modern recommender systems, increasing the energy consumption of recommender systems experiments [10]. This trend is driven by a shift from traditional algorithms like ItemKNN (or so-called good old-fashioned AI) to more sophisticated deep learning techniques [38, 61]. The increased energy consumption of deep learning results in higher carbon emissions, further exacerbating environmental challenges. With this backdrop, a relevant question is what is the environmental toll of recommender systems experiments?
However, the recommender systems community has paid little attention to the energy consumption and carbon emissions of their experiments [46]. This oversight is increasingly concerning, given the global consensus on the urgent need for actions to mitigate carbon emissions [33]. As the recommender systems community strives to advance technologies that improve user experiences, it must also confront the environmental repercussions and their impact on climate change, especially during the current crisis.
Therefore, our interest is to answer the question: What are the ecological costs of recommender systems research, past and present? In this paper, we answer the following research questions.
- RQ1: How large is the energy consumption of a modern recommender systems research paper?
- RQ2: How substantial is the energy consumption and performance trade-off between traditional and deep learning recommender system algorithms?
- RQ3: How has the carbon footprint of recommender systems experiments changed with the transition from traditional to deep learning algorithms?
In this work, we reproduce representative recommender systems experimental pipelines and show the extent of carbon emissions attributable to recommender systems experiments, providing a comparative analysis of recommender systems algorithms a decade apart. Our analysis is based on 79 full papers from the ACM RecSys conference in 2013 and 2023, respectively. Reproducing a representative experiment setup for each year enables us to conduct these experiments to directly measure their energy consumption and determine their carbon footprint across various hardware configurations, including laptops, workstations, and desktop PCs.
Our contribution is a comprehensive analysis of the carbon emissions associated with recommender system experiments and the reproduction of a representative recommender systems pipeline comparing 13 datasets and 23 algorithms from 2013 and 2023 on four hardware configurations. Our results indicate that a recommender systems research paper utilizing deep learning algorithms produces, on average, 3,297 kilograms of CO2 equivalents. In contrast to a paper utilizing traditional algorithms from 2013, a 2023 research paper emits approximately 42 times more CO2 equivalents. Furthermore, we show that the geographical location, i.e., the means of energy production (fossil or renewable), can change the carbon footprint of recommender systems research experiments by up to 12 times. Additionally, we found vast differences in the energy efficiency of different hardware configurations when performing recommender systems experiments, changing the carbon footprint of the same experiments by a factor of up to 10. We highlight the energy consumption and carbon emissions of recommender system experiments to foster awareness and the development of more sustainable research practices in the field, ultimately contributing to more sustainable recommender systems experiments and research.
The code used to execute and measure the experiments is publicly available in our GitHub repository and further contains documentation to ensure the reproducibility of our experiments.
Related Work
The impacts of greenhouse gases on the environment are extensively studied, with measurable effects seen in global warming and climate change. This research underscores the importance of addressing greenhouse gases for the well-being of humanity and life on Earth. According to meta-studies, scientists overwhelmingly agree that humans cause climate change [13, 31]. Additionally, tremendous efforts are being made to document the development of greenhouse gas emissions globally3. The greenhouse gas carbon dioxide (CO2) [7] is emitted in the generation of electricity when using fossil fuels4. Particularly relevant to applied researchers, optimistic estimations forecast that more than 7% of global electricity demand will be attributed to computing by 2030 [20].
Electricity carries a direct monetary value and a cost associated with the damage caused by greenhouse gas emissions from its production, commonly referred to as social cost [43]. Hence, due to the harmful effects of fossil fuel electricity production, there is growing interest in green computing [41]. In machine learning literature, energy consumption and carbon emissions from research experiments are well-known concerns [6, 34]. Green computing in machine learning presents unique challenges [49], particularly due to the shift to deep learning techniques, including, e.g., natural language processing [47] and computer vision [64]. Natural language processing tasks are frequently solved with large language models in cutting-edge recommender systems research [54].
The machine learning community actively provides guidelines and raises awareness for green and sustainable computing [23, 29]. Numerous software libraries have also been published to measure the carbon footprint of existing experiments [25]. However, despite these advancements, green and sustainable computing have yet to become established topics within recommender systems.
To our knowledge, only one paper has directly examined the carbon footprint of recommender systems [46]. This study, however, is limited to exploring the trade-off between algorithm performance and carbon footprint, relying on software-based power measurements rather than hardware-based analysis. Research on automated recommender systems has considered computing power requirements [50, 52], significantly impacting energy consumption. Additionally, another paper proposes an energy-efficient alternative to k-fold cross-validation [5], and recommender systems have been explored for their potential to enhance sustainability and energy efficiency in other domains [18, 24]. However, accurately estimating the global carbon footprint of recommender systems remains impossible without further research.
Our literature review reveals that current recommender systems papers do not openly disclose the estimated carbon footprint of their experiments. Furthermore, to our knowledge, no recommender systems publication outlets publicly release statements regarding the carbon footprint of submissions. An example of this in this area is ECIR 2024, which incorporated self-reported greenhouse gas emissions into its paper submissions, though no official results have been published yet. We conclude that while awareness of the carbon footprint of recommender systems experiments is increasing, it remains insufficiently low to make a significant impact.
Comparative Study: 2013 vs 2023
To answer our research questions, we reproduce measurements and estimations as accurately as possible. Therefore, we summarize the historical development of recommender systems experiments by analyzing research papers from 2023 and 2013, reflected through peer-reviewed papers at a conference. To this end, we present our analysis of all full papers accepted in the main track at ACM RecSys in 2013 (32 papers [1]) and 2023 (47 papers [2]). All papers considered in this analysis are published in the ACM Digital Library.In the following paragraphs, we examine these recommender systems papers for hardware specifications, software libraries, design decisions in experimental pipelines, the availability of open-source code for reproducibility, and used datasets.
Hardware: Only 15 (32%) full papers from ACM RecSys 2023 detail the hardware used for experiments, and consequently, 32 (68%) of the papers do not report this information. All these 15 papers explicitly report usage of Nvidia GPUs, with seven specifically mentioning the Nvidia v100 GPU (released in 2017).
Looking back at papers published at ACM RecSys 2013, only 6 out of 32 (19%) contain information about the hardware used, meaning 26 (81%) do not contain hardware information. Contrary to 2023, none of the papers from 2013 mention using a GPU. However, all 6 papers that disclose their hardware utilize an Intel Xeon CPU.
Libraries: At ACM RecSys 2023, 18 (38%) papers use PyTorch, and 6 (13%) papers use TensorFlow implementing deep learning recommender systems. RecBole [55] is used by 5 (11%) papers, making it the most popular library designed explicitly for recommender systems. While 13 (28%) papers from 2023 do not specify the library used, they all implement deep learning algorithms. The remaining 5 (11%) papers report using one of the following libraries: Elliot [3], ReChorus [51], Bambi [9], FuxiCTR [65], or CSRLab [63].
This contrasts the patterns observed in ACM RecSys 2013 papers. The majority of papers, 27 (84%) do not report using any open libraries. Instead, they rely on private algorithm implementations. Only 5 (16%) papers report using libraries, which include MyMediaLite [19], Apache Mahout [4], InferNet [36], and libpMF [58]. This shift highlights a considerable evolution in adopting standardized libraries within recommender systems over the past decade. Arguably, the feasibility of reproducing a recommender systems paper has increased over time, at least in terms of software.
Experimental Pipeline: Between papers from 2023 and 2013, the experimental pipeline remains consistent, but there are significant differences in the algorithms and datasets. For instance, the holdout split is the most popular data splitting technique, used in 20 (42%) of the 2023 papers and 20 (63%) of the 2013 papers. Grid search is also the favored optimization technique in both 2023 and 2013. Additionally, 22 (47%) papers in 2023 and 20 (63%) in 2013 do not employ dataset pruning, although n-core pruning appears to have gained notable popularity, appearing in 19 (40%) papers in 2023.
One of the most significant differences lies in the evaluation metrics used: nDCG is the predominant metric in 2023, used in 32 (68%) papers, whereas, in 2013, Precision is the most popular one, appearing in 13 (40%) papers, followed by RMSE and nDCG, each used in 5 (16%) papers. This is partly because 44 (94%) of papers in 2023 focus on top-n ranking prediction tasks, while 18 (56%) of papers in 2013 focus on rating prediction tasks.
Open-Source Code: Only 18 (38%) of ACM RecSys 2023 papers do not contain links to their source code. On the other hand, 29 (62%) make their code available, with all but 2 hosting it on GitHub and the remaining hosting it on their organization’s website. However, 3 (6%) repositories linked in these papers are empty or unreachable. Only 1 (3%) paper from ACM RecSys 2013 shares code.
Datasets: On average, papers from ACM RecSys 2023 include three datasets. The most frequent datasets are from the Amazon2018 series, appearing in 15 (32%) papers, followed by the MovieLens datasets, of which MovieLens-1M is used in 11 (23%) papers, while MovieLens-100K, MovieLens-10M, and MovieLens-20M are used in 2 (4%) papers. Other commonly used datasets are LastFM in 6 (13%) papers, Yelp-2018 in 5 (11%) papers, and Gowalla in 5 (11%) papers.
On average, papers at ACM RecSys 2013 include two distinct datasets in their experimental pipeline. The most frequently used datasets are the MovieLens datasets, used in 10 (31%) papers. Neither of the popular Amazon datasets were available in 2013. Other commonly used datasets include the LastFM dataset, used in 4 (13%) papers, and the Netflix Prize dataset, used in 3 (9%) papers.
Method
We measure the energy consumption of running 23 algorithms on 13 datasets with a smart power plug. To assess the impact of hardware on energy efficiency, we run the experiments on four distinct computers. We also estimate the carbon footprint by assessing the carbon emissions related to electricity generation in five locations. Our experimental pipeline is based on our research papers analysis, ensuring representative data collection (Section 3). All design decisions are derived from this analysis unless otherwise specified.
Experimental Pipeline
We randomly divide each of the 13 datasets into three splits, where 60% of the data is for training, 20% for validation, and 20% for testing. Since our work focuses on energy consumption rather than maximizing performance and generalizability, we neither employ cross-validation nor repeat experiments. While this decision comes at the cost of reliability and performance in terms of accuracy, our goal is not to optimize the recommender models to beat a baseline but to measure the power consumption of a characteristic recommender system experiment. We measure performance by nDCG@10 for top-n ranking predictions and RMSE for rating predictions. Furthermore, we use the default hyperparameter settings provided by the libraries instead of optimizing them. We make these decisions to minimize unnecessary energy consumption. All deep learning algorithms are trained for 200 epochs, with model validation after every fifth epoch to facilitate early stopping.
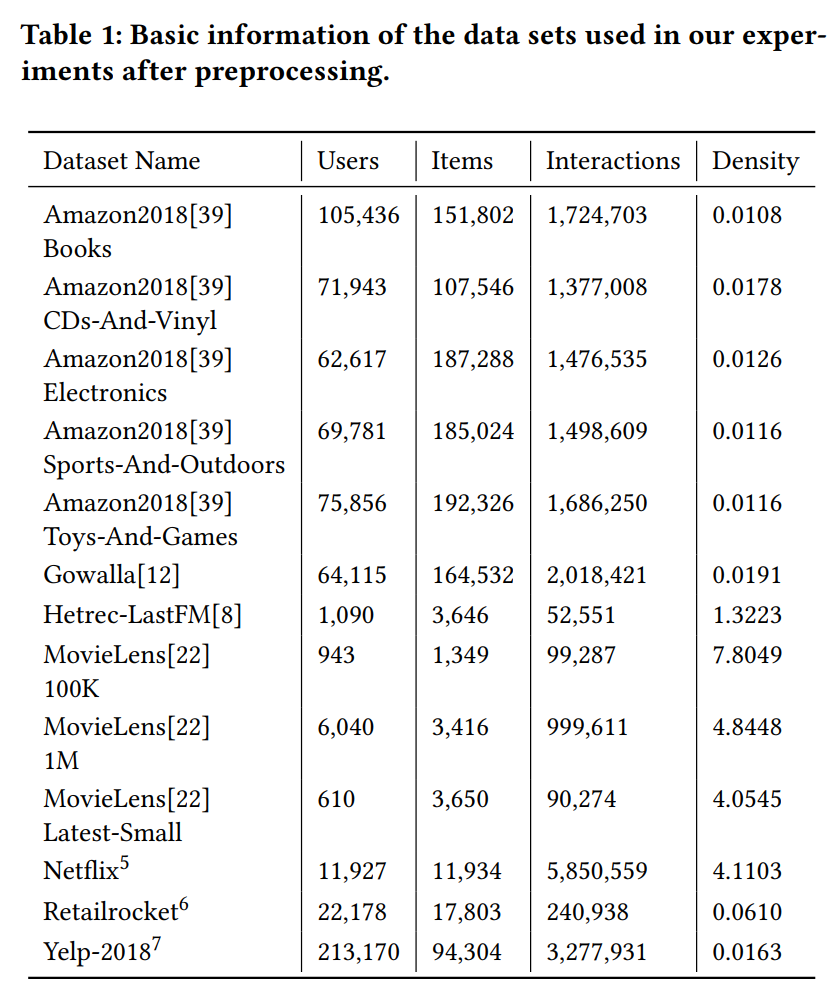
Datasets: Based on our research paper analysis (Section 3), we include 13 datasets in our experiments and refer to Table 1 for an overview. For top-n prediction tasks, we convert rating prediction datasets according to practice that is common in our paper analysis[11, 32, 56, 66]. Furthermore, we prune all datasets such that all included users and items have at least five interactions, commonly known as five-core pruning [48, 59, 60]. Table 1 shows the dataset statistics of all included datasets for the preprocessed datasets.
Algorithms: Based on our research paper analysis (Section 3), we include 23 frequently used algorithms in our experiments. The algorithm implementations are from RecBole [55] (indicated by RB), RecPack [35] (indicated by RP) and LensKit [15] (indicated by LK). We run algorithms from RecBole on a GPU while we run algorithms from LensKit and RecPack on a CPU. Table 2 shows all algorithmic implementations used in our experiments.

Representative Pipeline
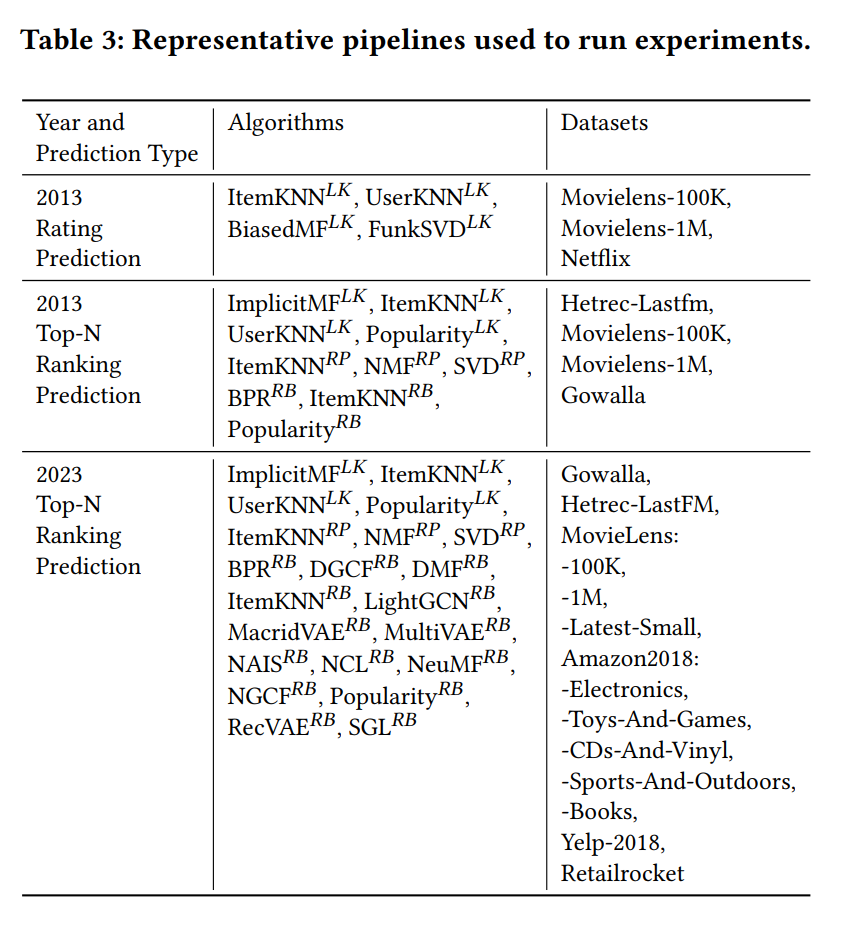
Our research paper study indicates that experimental pipelines from 2013 and 2023 exhibit notable differences (Section 3). For instance, in 2023, all but one paper focused on top-n ranking prediction tasks, whereas in 2013, around half of the papers focused on rating prediction tasks. Additionally, in 2023, experiments often utilize datasets from the Amazon-2018 series, which were not available in 2013. Consequently, we introduce three distinct representative pipelines to account for these differences. Table 3 provides an overview of the algorithms and datasets used for specific pipelines.
Calculating Greenhouse Gas Emission
To calculate the greenhouse gas emissions from recommender systems experiments, we first record the electricity consumption and translate the consumption into equivalent emissions.
Measuring Electrical Energy Consumption. To precisely measure the energy consumption of recommender system experiments, we equip each computer in our experimental setup with a commercially available off-the-shelf smart power plug8. This enables us to measure energy consumption in kilowatt-hours (kWh) at half second intervals. We then align the power plug’s measurements with the experiments based on timestamps. Our measurements capture the entire hardware’s energy usage, covering components such as cooling, power supply, CPU, GPU, and memory.
Calculating Greenhouse Gas Emissions Based on Electricity Consumption. We convert the measured energy consumption in kWh into carbon dioxide equivalents (CO2e) utilizing the comprehensive dataset provided by Ember9. The Ember datasets merge data from the European Electricity Review and information from various original data providers into a singular dataset10.The Ember dataset features a conversion rate from kWh to grams of carbon dioxide emissions equivalents (gCO2e). CO2e represent the greenhouse gas emissions released and the overall environmental impact of electricity generation. Since the hardware does not directly impact the environment by, e.g., emitting greenhouse gases, we utilize the carbon dioxide equivalents associated with the electricity generation process of the consumed energy. The gCO2e conversion rate linked to electricity generation varies notably based on the method of production [26]. Electricity sourced from renewable energy, such as hydropower, typically has a lower carbon footprint than coal combustion. Different regions employ diverse energy generation methods, so we use the global average conversion rate and compare various geographical locations.
Hardware
We conduct all experiments across four computers with different hardware configurations from different years to assess the impact of hardware efficiency on energy consumption and, consequently, the carbon footprint. Computer hardware has become increasingly efficient over the years [27]. We perform experiments on four computers spanning the last decade to evaluate the impact on hardware efficiency and whether the improvement can offset the energy demands of transitioning to deep learning. We present the hardware specifications used in our experiments in Table 4.

Results
Our results demonstrate the energy consumption, the trade-offs between energy and performance, and the carbon footprint associated with the 2013 and 2023 ACM RecSys full paper experiments.
The energy consumption of a 2023recommender systems research paper
The Energy Consumption of an Algorithm and Dataset. Based on our experiments, we estimate the energy consumption of a single run of one recommender systems algorithm on one dataset to be, on average, 0.51 kWh (Fig. 1a).
Energy consumption varies among algorithms and datasets. Relatively simple algorithms like Popularity and ItemKNN consume only 0.007 kWh and 0.04 kWh, respectively (average over twelve datasets used for experiments representing 2023). Some recent deep learning algorithms consume a relatively low amount of energy, e.g., DMF and LightCGN consume 0.13 kWh and 0.12 kWh, respectively (average over twelve datasets used for 2023 experiments). Contrasting, the most “expensive” algorithms – MacridVAE and DCGF consume, on average, 1.79 kWh and 1.45 kWh, respectively. Consequently, the most expensive algorithm (MacridVAE), regarding electricity consumption, requires 257 times as much energy as the cheapest algorithm (Popularity).
The energy consumption of individual algorithms on different datasets is even higher. Popularity consumes only 0.000036 kWh on Movielens-Latest-Small but 0.03 kWh on the Yelp-2018 dataset (factor 800). The deep learning algorithm DGCF consumes 0.005 kWh on Hetrec-LastFM but 6.6 kWh on Yelp-2018 (factor 1,444).
When executing algorithms over larger datasets, energy consumption increases compared to executing the same algorithm on smaller data. For example, the average recommender systems algorithm consumes 0.001 kWh on Hetrec-LastFM with 53 thousand interactions and 1.56 kWh, 1,560 times more energy, on Yelp-2018 with 3.3 million interactions (Fig. 1b).
However, the energy consumption per dataset is not solely dependent on the number of interactions. Although Amazon2018- Electronics has ~25% fewer interactions than Gowalla (1.5M vs. 2M; Fig. 1b), algorithms running on Amazon2018-Electronics consume, on average, 18% more energy (0.728 kWh/0.617 kWh). Similarly, even though Movielens-1M includes around half the interactions of Gowalla (1M vs. 2M), algorithms on Movielens-1M consume only 10% of the energy Gowalla needs (0.06 kWh vs. 0.6 kWh).
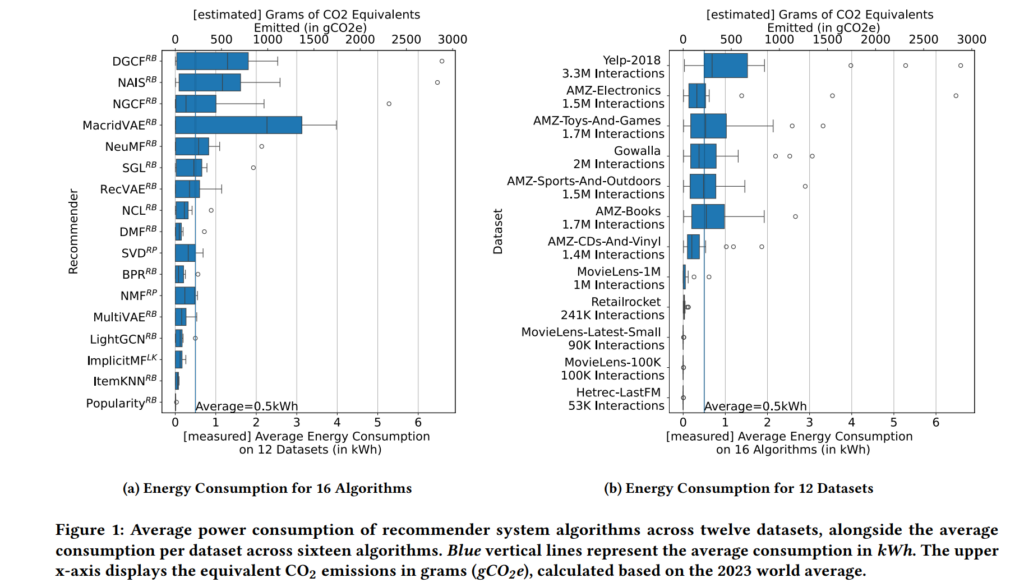
The Energy Consumption of an Experimental Pipeline. Based on our experiments, we estimate the energy consumption of are presentative 2023 recommender systems experimental pipeline to be 171.36 kWh. Through the paper analysis described in Section 3, we found that a 2023 recommender systems experimental pipeline includes, on average, seven recommender systems algorithms. Additionally, the algorithm performance is, on average, evaluated on three datasets. Furthermore, a representative experimental pipeline performs hyperparameter optimization through grid search on 16 configurations per algorithm. Since one algorithm consumes, on average, 0.51 kWh (Fig. 1, left), the energy consumption of an experimental pipeline is calculated as follows:
7 × 3 × 16 × 0.51 kWh = 171.36 kWh.
The Energy Consumption of a Paper. Based on experiments and our paper study (Section 3), we estimate the energy consumption of a representative 2023 paper to be 6,854.4 kWh.
The energy consumption estimation of 171.36 kWh per recommender systems experimental pipeline only accounts for the direct energy consumption during the experimental run (Section 5.1.2). The estimation excludes energy costs for preliminary activities such as algorithm prototyping, initial test runs, data collection, data preprocessing, debugging, and potential re-running of experiments due to pipeline errors. Therefore, to approximate the total energy impact of a recommender systems paper, we account for these additional energy costs by introducing an additional factor.
We interviewed the authors of Elliot [3], RecPack [35], LensKit [15], and recommender systems practitioners [17] asking them to estimate a factor of the energy consumption overhead of a recommender systems paper compared to running the experimental pipeline once. Their median answer was 40. We multiplied the energy consumption of experimental pipelines accordingly. Following this, we estimate the energy consumption of experiments for the results presented in a recommender systems paper ranges to be 6,854.4 kWh.
Energy Consumption and PerformanceTrade-Off
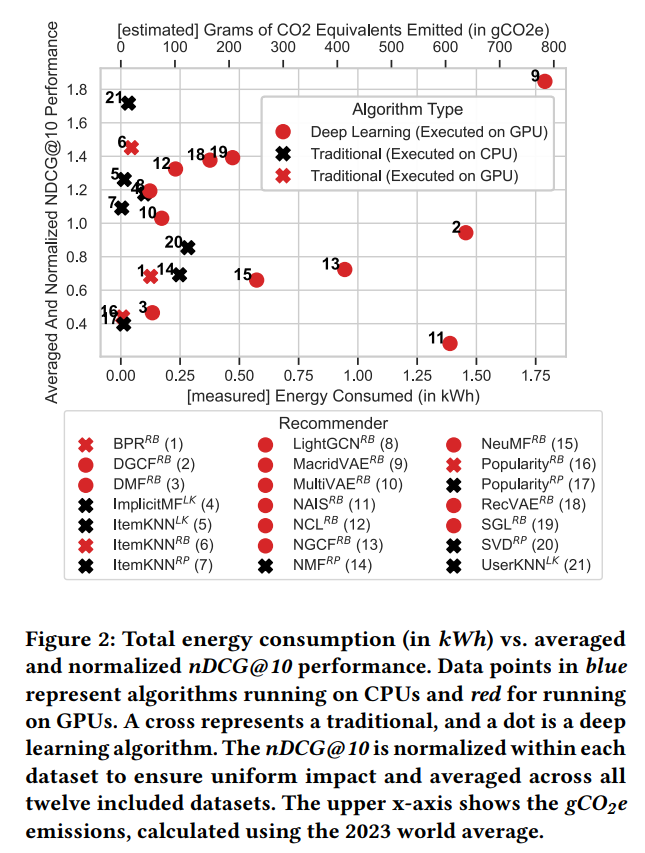
Our results demonstrate that higher energy consumption does not necessarily lead to better performance (Fig. 2). Two of the three top-performing algorithms (UserKNN𝐿𝐾 and ItemKNN𝑅𝐵) are traditional nearest neighbor algorithms that both consume on average around 0.040 kWh for a single run on one dataset (average of twelve datasets used for 2023 experiments). In contrast, the third, a deep learning algorithm (MacridVAE𝑅𝐵) consumes, on average, 45 times more energy at 1.8 kWh per run on one dataset.
In general, our results show that deep learning algorithms consume eight times more energy than traditional algorithms for a single run, on average, on one dataset (0.09 kWh vs. 0.68 kWh) without achieving a higher average and normalized nDCG@10 score. One comparison that further illustrates the energy consumption and performance trade-off between deep learning and traditional algorithms is the comparison between the MacridVAE𝑅𝐵 (deep learning) and the UserKNN𝐿𝐾 (traditional) algorithms. While both algorithms achieve around the same normalized and averaged nDCG@10 performance (1.8 vs 1.7), MacridVAE𝑅𝐵 consumes almost 60 times more energy (1.79 kWh vs. 0.03 kWh).
As widely known and highlighted by current research, hyperparameter optimization and randomness impacts the algorithm performance [44, 53]. We acknowledge that tuning hyperparameters and repeating experiments could alter our results. However, this would likely increase the energy consumption disparity between deep learning and traditional algorithms. For instance, if we optimize the hyperparameters of MacridVAE𝑅𝐵 and UserKNN𝐿𝐾 through a grid search with 16 configurations and repeat the process with five different seeds, MacridVAE𝑅𝐵 would consume 143.2 kWh, while UserKNN𝐿𝐾 would only use 2.4 kWh (factor of 60).
The energy consumption difference between deep learning and traditional algorithms is not solely due to GPU usage. While GPUs consume more energy than CPUs, implementation and complexity also play a role. For instance, ItemKNN𝑅𝐵 on a GPU consumes no significantly more energy than CPU-based KNN counterparts (Fig. 2).
Carbon Footprint and Trends
The Carbon Footprint of Experiments at ACM Recsys 2023. Based on our experiments, we estimate that running all ACM RecSys 2023 full paper experiments emitted 886.9 metric tonnes of CO2 equivalents. Our CO2e estimation is based on the number of submissions and the conversion factors from kWh to gCO2e. The carbon footprint of all ACM RecSys 2023 full papers is closely tied to the number of submissions received. The conference accepted 47 full papers out of 269 submissions. Since the submissions involved running experiments, every submission added to the total carbon footprint of the ACM RecSys 2023 experiments. Consequently, we account for all 269 submissions in our analysis.Our carbon footprint estimation is further based on the world average conversion factor of 481 gCO2e per kWh [16]. We estimate that a full paper experimental pipeline consumes, on average, 6,854.4 kWh (Section 5.1). With the conversion factor of 481 gCO2e per kWh, the carbon emissions of the 2023 ACM RecSys conference experiments in metric tonnes of CO2e are calculated as follows:
6, 854.4kWh × 481gCO2e × 269 (𝑠𝑢𝑏𝑚𝑖𝑠𝑠𝑖𝑜𝑛𝑠) = 886.9 𝑇𝐶𝑂2𝑒
To illustrate, 886.9 TCO2e is the equivalent of 384 passenger flights from New York (USA) to Melbourne (Australia) [30]. Or the amount of CO2e that, on average, one tree sequesters in 80,600 years [14].
The Geographical Impact on the Carbon Footprint. Variations in energy generation across different geographical locations affect carbon footprint by as much as 1200% (45 vs. 535 gCO2e). Each location has its own kWh to gCO2e conversion factor, which reflects the carbon intensity of its electricity generation. The conversion factor is based on the energy sources of the respective geographical location. For instance, we ran our experiments in a geographical location that mainly utilizes renewable energy sources such as wind and hydropower [62]. Unlike this geographical location, some regions in Asia depend on coal [42]. As a result, our conversion factor from kWh to gCO2 is twelve times lower than that of the Asian region (45 vs. 535 [16].
If all experiments from ACM RecSys 2023 had been conducted in Sweden, the carbon emission estimation would have been reduced to 83 metric tonnes (90% less than 886.9 TCO2e). In contrast, running the experiments in Asia, our estimation would have increased our carbon emission estimation by 99.6 metric tonnes of CO2e (886.9 vs. 986.5 TCO2e) Since no paper from ACM RecSys 2023 reported the data center or location where the experiments were conducted, we used the world average conversion factor of 481 gCO2e per kWh[16] to convert kWh to gCO2e to estimate the carbon emissions.
The amount of CO2 emitted by experiments is not solely determined by the location. Some data centers operate mainly on renewable energy regardless of their location. For instance, Amazon reports that their data centers used for AWS cloud services predominantly utilize renewable sources11. Consequently, these specific data centers may have a conversion factor from kWh to gCO2e that differs from the general rate of their location.
The Hardware Impact on the Carbon Footprint. The CO2e emissions of recommender systems experiments are influenced by more than geographical location, algorithm types, and dataset characteristics. The type of hardware executing experiments can also affect the CO2e emissions by a factor of up to ten. For example, the same experiments emit 14.4 gCO2e when executed on a MacBook Pro (M1) but 163.5 gCO2e when executed on a modern workstation. Various hardware components, architectures, and cooling methods affect the energy consumption of recommender system experiments. Based on our experiments, a modern workstation consumes, on average, five times more energy compared to a Mac Studio (0.33 vs. 0.07 kWh) and ten times more energy compared to the MacBook Pro M1 (0.33 vs. 0.03 kWh).
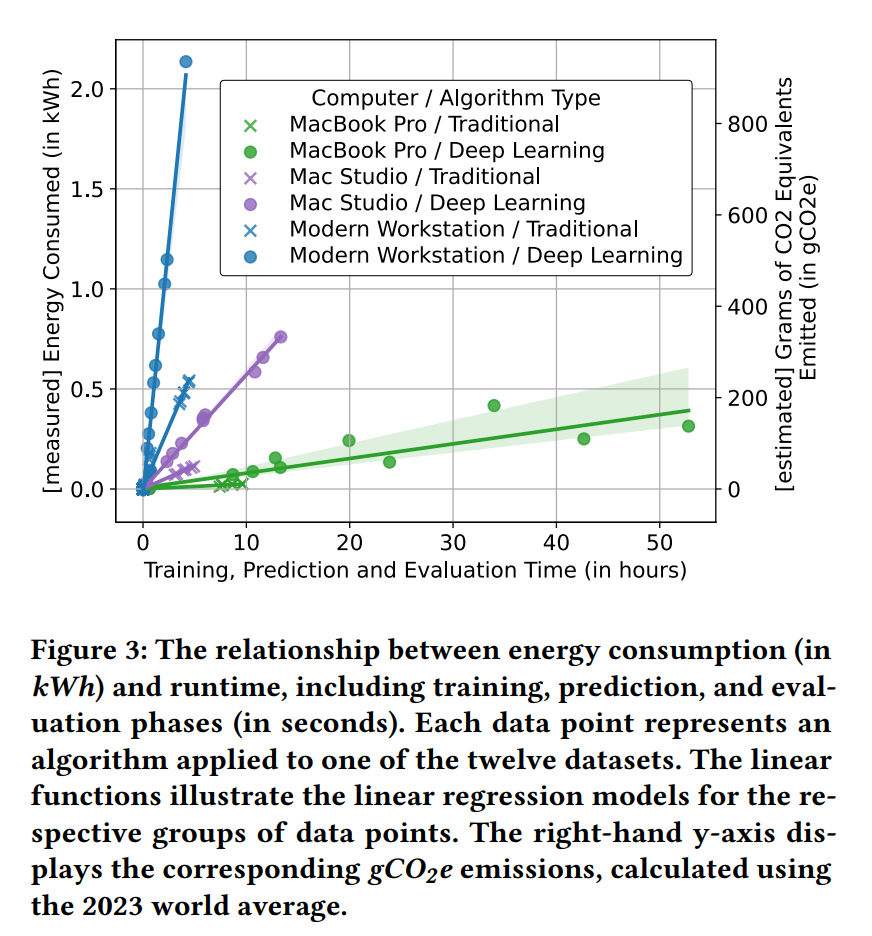
Different hardware types do not only affect the energy consumption but also the running time of a recommender systems experiment. For instance, while a modern workstation uses, on average, ten times more energy than an Apple MacBook Pro (M1), it completes the experiments, on average, in only one-third of the time (Fig. 3). Therefore, it is possible to save energy by running an experiment on a MacBook Pro (M1) if you accept an increase in running time.
Overall, our results show a linear trend between energy consumption and runtime across various hardware types (Fig. 3). Although the slopes of the graphs vary, a consistent linear pattern is evident. This relationship suggests that a longer runtime is associated with increased energy consumption.
Even though a modern workstation consumes more energy, we run experiments on it because not all algorithms are compatible with Apple’s ARM architecture.
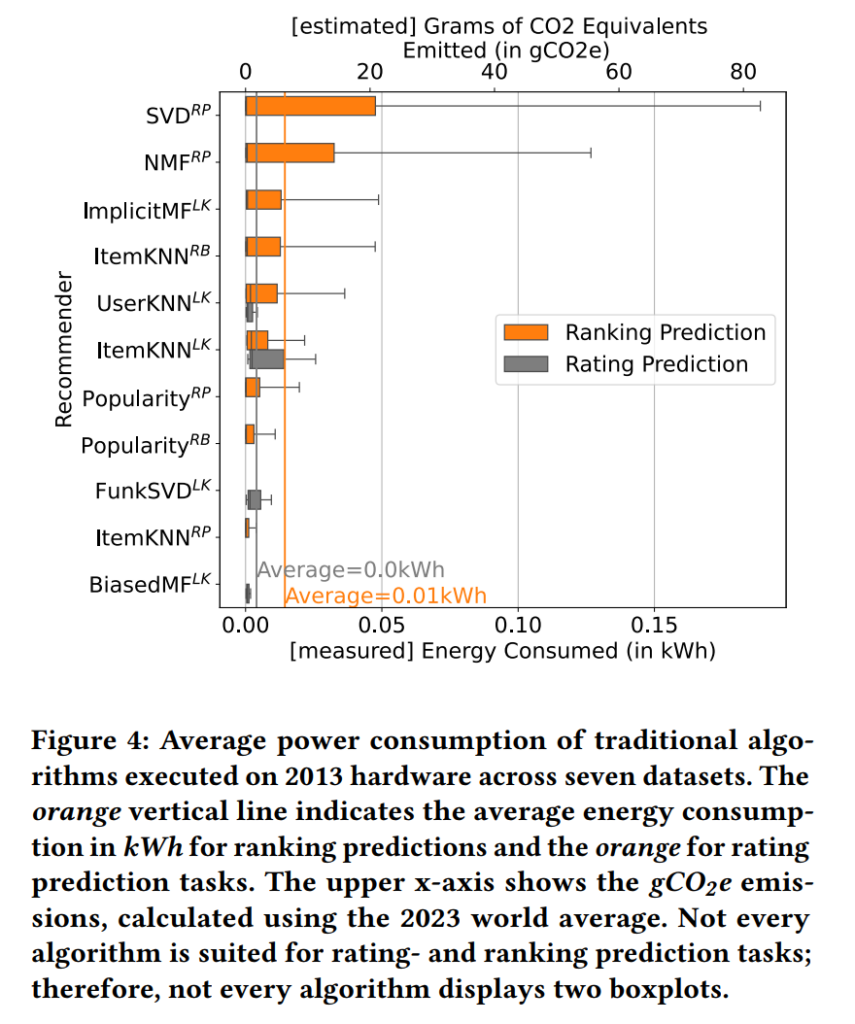
The Carbon Footprint of Recommender Systems 2013 vs. 2023. The carbon footprint of recommender systems experiments in 2023 compared to 2013 has, on average, increased by a factor of 42 (7.09 gCO2e in 2013 vs. 294.9 gCO2e in 2023, Fig. 5, World Average).
Simple ranking prediction algorithms used in 2013 consumed, on average, five times less energy per run on one 2013 dataset using 2013 hardware (0.1 kWh, see Fig. 4) compared to similar algorithms in 2023 executed on 2023 hardware (0.51 kWh, see Fig. 1). In 2013, no algorithm used, on average, more than 0.2 kWh per run on one dataset using 2013 hardware (Fig. 4). In contrast, all deep learning algorithms in 2023 consume, on average, more than 0.2 kWh per run on one dataset with 2023 hardware. The most energy intensive algorithms in 2023 use more than six kWh per run (Fig. 1). While rating prediction was frequently used in 2013, the energy consumption for rating prediction is, due to prediction times, lower than for ranking prediction tasks (Fig. 4).
The shift towards more complex deep learning algorithms such as DGCF or MacridVAE and larger datasets like Yelp-2018, compared to simpler algorithms like Popularity or ItemKNN and smaller datasets such as Hetrec-LastFM used in 2013, can, in the worst case, increase energy consumption of more than 100,000 times. For example, running the Popularity algorithm on Hetrec-LastFM and hardware from 2013 requires only 0.000049 kWh while running DGCF on dataset Yelp-2018 required 6.6 kWh on 2023 hardware, i.e., a factor of around 134,000.
The increased usage of clean energy sources and improved hardware efficiency in 2023, compared to 2013, does not compensate for the increase in carbon emissions due to the use of deep learning algorithms and larger datasets. A deep learning algorithm running on a 2023 dataset using 2023 hardware emits, on average, 42 times more CO2e than a traditional algorithm on a 2013 dataset using 2013 hardware (7.09 gCO2e in 2013 vs. 294,9 gCO2e in 2023, Fig. 5, World Average). This estimation already includes the benefit of a better kWh to gCO2e conversion factors, improved by 62 gCO2e due to the more frequent use of clean energy resources [16].
It is important to highlight that our analysis used hardware and algorithms from 2013 but not the exact software implementations used in the original papers. It was infeasible to retrieve old, unmaintained, non-centrally hosted software. Consequently, many experiments likely used self-implemented algorithms. Compared to self-implemented algorithms, standardized software libraries could potentially change the efficiency, suggesting that the observed disparity in energy consumption between traditional and deep learning models might diverge.
Discussion
Our analysis highlights the significant environmental impact of full papers from the 2023 ACM Recommender Systems conference. We found that deep learning algorithms, when compared to traditional machine learning, consume substantially more energy without necessarily delivering better performance. Additionally, the carbon footprint and environmental impact of recommender systems experiments have dramatically increased over the past decade.
We do not advocate abandoning deep learning algorithms but aim to raise awareness about the environmental impact of the trend toward deep learning-focused research. We encourage researchers and practitioners to document the experimental pipelines, computational overheads, hardware, and energy consumption in their publications. These details can help in understanding the environmental impact, highlight the energy demands, and reveal potential areas for energy efficiency improvements and reproducibility of recommender systems experiments.
Furthermore, we emphasize the importance of carefully selecting algorithms and datasets for recommender systems experiments. The environmental impact of deep learning algorithms can notably differ depending on the chosen algorithms and datasets. Researchers can minimize unnecessary computations by using efficient hardware or designing experimental recommender systems pipelines and thus reduce their environmental impact. We also draw attention to the impact of hardware and geographic location on recommender systems experiments. If computers in different geographic locations are available, comparing the efficiency, hardware requirements, and energy source of the specific location can help reduce the environmental impact of running the experimental pipeline.
Conclusions
We reveal that the energy consumption of an average recommender systems research paper is approximately 6,854.4 kWh (RQ1). Deep learning algorithms consume, on average, eight times more energy than traditional algorithms without achieving higher performance (RQ2). The carbon footprint of recommender systems experiments has increased significantly, with experiments from 2023 emitting approximately 42 times more CO2e when compared to experimental pipelines from 2013 (RQ3).
We want to raise awareness about the significant environmental impact of deep learning-focused research. It is crucial that future publications include thorough documentation of the entire experimental pipeline, including computational overhead, hardware specifications, and energy consumption. This transparency is not only essential for enhancing reproducibility but also for identifying potential areas for energy efficiency improvements.
Moreover, careful selection of algorithms and datasets is crucial, as the environmental impact of deep learning algorithms can vary significantly. Researchers can design more efficient experimental pipelines to minimize unnecessary computations and reduce environmental impact. Additionally, considering the impact of hardware and geographic location on experiments is vital. Comparing the efficiency, hardware requirements, and energy sources across different locations can further mitigate the environmental impact of experimental pipelines. We conducted all our experiments in Sweden, utilizing approximately 6,000 kWh of electricity, which corresponds to about 271.6 kilograms of CO2e. We planted 42 trees with One Tree Planted to offset our carbon emissions.
Raising awareness about energy consumption and environmental impact can catalyze the development of more sustainable practices, benefiting the environment and recommender systems.
Acknowledgements
This work was in part supported by: (1) funding from the Ministry of Culture and Science of the German State of North Rhine Westphalia, grant no. 311-8.03.03.02-149514, and (2) two ERASMUS+ Short-Term Doctoral Mobility Traineeships from the European Commission. Furthermore, we are grateful for the support of Moritz Baumgart.
References
[1] 2013. RecSys ’13: Proceedings of the 7th ACM conference on Recommender systems (Hong Kong, China). Association for Computing Machinery, New York, NY, USA.
[2] 2023. RecSys ’23: Proceedings of the 17th ACM Conference on Recommender Systems (Singapore, Singapore). Association for Computing Machinery, New York, NY, USA.
[3] Vito Walter Anelli, Alejandro Bellogín, Antonio Ferrara, Daniele Malitesta, Felice Antonio Merra, Claudio Pomo, Francesco Maria Donini, and Tommaso Di Noia. 2021. Elliot: A Comprehensive and Rigorous Framework for Reproducible Recommender Systems Evaluation. In SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, Fernando Diaz, Chirag Shah, Torsten Suel, Pablo Castells, Rosie Jones, and Tetsuya Sakai (Eds.). ACM, 2405–2414. https://doi.org/10.1145/3404835.3463245
[4] Robin Anil, Gokhan Capan, Isabel Drost-Fromm, Ted Dunning, Ellen Friedman, Trevor Grant, Shannon Quinn, Paritosh Ranjan, Sebastian Schelter, and Özgür Yilmazel. 2020. Apache Mahout: machine learning on distributed dataflow systems.J. Mach. Learn. Res. 21, 1, Article 127 (jan 2020), 6 pages.
[5] Joeran Beel, Lukas Wegmeth, and Tobias Vente. 2024. e-fold cross-validation: A computing and energy-efficient alternative to k-fold cross-validation with adaptive folds. https://doi.org/10.31219/osf.io/exw3j
[6] Semen Andreevich Budennyy, Vladimir Dmitrievich Lazarev, Nikita Nikolaevich Zakharenko, Aleksei N Korovin, OA Plosskaya, Denis Valer’evich Dimitrov, VS Akhripkin, IV Pavlov, Ivan Valer’evich Oseledets, Ivan Segundovich Barsola, et al. 2022. Eco2ai: carbon emissions tracking of machine learning models as the first step towards sustainable ai. In Doklady Mathematics, Vol. 106. Springer, S118–S128.
[7] Michelle Cain, John Lynch, Myles R. Allen, Jan S. Fuglestvedt, David J. Frame, and Adrian H Macey. 2019. Improved calculation of warming-equivalent emissions for short-lived climate pollutants. npj Climate and Atmospheric Science 2, 1 (Sept. 2019). https://doi.org/10.1038/s41612-019-0086-4
[8] Ivan Cantador, Peter Brusilovsky, and Tsvi Kuflik. 2011. Second Workshop on Information Heterogeneity and Fusion in Recommender Systems (HetRec2011). In Proceedings of the Fifth ACM Conference on Recommender Systems (Chicago, Illinois, USA) (RecSys ’11). Association for Computing Machinery, New York, NY, USA, 387–388. https://doi.org/10.1145/2043932.2044016
[9] Tomás Capretto, Camen Piho, Ravin Kumar, Jacob Westfall, Tal Yarkoni, and Osvaldo A Martin. 2022. Bambi: A Simple Interface for Fitting Bayesian Linear Models in Python. Journal of Statistical Software 103, 15 (2022), 1–29. https: //doi.org/10.18637/jss.v103.i15
[10] Chunlei Chen, Peng Zhang, Huixiang Zhang, Jiangyan Dai, Yugen Yi, Huihui Zhang, and Yonghui Zhang. 2020. Deep Learning on Computational-ResourceLimited Platforms: A Survey. Mobile Information Systems 2020 (March 2020), 8454327. https://doi.org/10.1155/2020/8454327
[11] Huiyuan Chen, Xiaoting Li, Vivian Lai, Chin-Chia Michael Yeh, Yujie Fan, Yan Zheng, Mahashweta Das, and Hao Yang. 2023. Adversarial Collaborative Filtering for Free. In Proceedings of the 17th ACM Conference on Recommender Systems (Singapore, Singapore) (RecSys ’23). Association for Computing Machinery, New York, NY, USA, 245–255. https://doi.org/10.1145/3604915.3608771
[12] Eunjoon Cho, Seth A. Myers, and Jure Leskovec. 2011. Friendship and Mobility: User Movement in Location-Based Social Networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (San Diego, California, USA) (KDD ’11). Association for Computing Machinery, New York, NY, USA, 1082–1090. https://doi.org/10.1145/2020408.2020579
[13] John Cook, Naomi Oreskes, Peter T Doran, William R L Anderegg, Bart Verheggen, Ed W Maibach, J Stuart Carlton, Stephan Lewandowsky, Andrew G Skuce, Sarah A Green, Dana Nuccitelli, Peter Jacobs, Mark Richardson, B”arbel Winkler, Rob Painting, and Ken Rice. 2016. Consensus on consensus: a synthesis of consensus estimates on human-caused global warming. Environmental Research Letters 11, 4 (April 2016), 048002. https://doi.org/10.1088/1748-9326/11/4/048002
[14] Department for Business, Energy & Industrial Strategy. 2020. Conversion Factors 2020 Methodology. Technical Report. Government of the United Kingdom. https://assets.publishing.service.gov.uk/media/5f119b673a6f405c059f6060/ conversion-factors-2020-methodology.pdf
[15] Michael D. Ekstrand. 2020. LensKit for Python: Next-Generation Software for
Recommender Systems Experiments. In Proceedings of the 29th ACM Interna-
tional Conference on Information & Knowledge Management (Virtual Event, Ire-
land) (CIKM ’20). Association for Computing Machinery, New York, NY, USA,
2999–3006. https://doi.org/10.1145/3340531.3412778
[16] Ember and Energy Institute. 2024. Carbon intensity of electricity generation – Em-
ber and Energy Institute. https://ourworldindata.org/grapher/carbon-intensity-
electricity. Yearly Electricity Data by Ember; Statistical Review of World Energy
by Energy Institute. Dataset processed by Our World in Data.
[17] Kim Falk and Morten Arngren. 2023. Recommenders In the wild – Practical
Evaluation Methods. In Proceedings of the 17th ACM Conference on Recommender
Systems (Singapore, Singapore) (RecSys ’23). Association for Computing Machin-
ery, New York, NY, USA, 1. https://doi.org/10.1145/3604915.3609498
[18] Alexander Felfernig, Manfred Wundara, Thi Ngoc Trang Tran, Seda Polat-Erdeniz,
Sebastian Lubos, Merfat El Mansi, Damian Garber, and Viet Man Le. 2023. Rec-
ommender systems for sustainability: overview and research issues. Frontiers in
Big Data 6 (30 Oct. 2023). https://doi.org/10.3389/fdata.2023.1284511 Publisher
Copyright: Copyright © 2023 Felfernig, Wundara, Tran, Polat-Erdeniz, Lubos, El
Mansi, Garber and Le..
[19] Zeno Gantner, Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme.
MyMediaLite: A Free Recommender System Library. In 5th ACM Interna-
tional Conference on Recommender Systems (RecSys 2011) (Chicago, USA).
[20] Udit Gupta, Young Geun Kim, Sylvia Lee, Jordan Tse, Hsien-Hsin S. Lee, Gu-Yeon
Wei, David Brooks, and Carole-Jean Wu. 2021. Chasing Carbon: The Elusive
Environmental Footprint of Computing. In 2021 IEEE International Symposium
on High-Performance Computer Architecture (HPCA). 854–867. https://doi.org/10.
1109/HPCA51647.2021.00076
[21] James Hansen, Pushker Kharecha, Makiko Sato, Valerie Masson-Delmotte, Frank
Ackerman, David J Beerling, Paul J Hearty, Ove Hoegh-Guldberg, Shi-Ling Hsu,
Camille Parmesan, et al. 2013. Assessing “dangerous climate change”: Required
reduction of carbon emissions to protect young people, future generations and
nature. PloS one 8, 12 (2013),
[22] F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History
and Context. ACM Trans. Interact. Intell. Syst. 5, 4, Article 19 (dec 2015), 19 pages.
https://doi.org/10.1145/2827872
[23] Peter Henderson, Jieru Hu, Joshua Romoff, Emma Brunskill, Dan Jurafsky, and
Joelle Pineau. 2020. Towards the Systematic Reporting of the Energy and Carbon
Footprints of Machine Learning. Journal of Machine Learning Research 21, 248
(2020), 1–43. http://jmlr.org/papers/v21/20-312.html
[24] Yassine Himeur, Abdullah Alsalemi, Ayman Al-Kababji, Faycal Bensaali, Abbes
Amira, Christos Sardianos, George Dimitrakopoulos, and Iraklis Varlamis. 2021.
A survey of recommender systems for energy efficiency in buildings: Principles,
challenges and prospects. Information Fusion 72 (2021), 1–21. https://doi.org/10.
1016/j.inffus.2021.02.002
[25] Mathilde Jay, Vladimir Ostapenco, Laurent Lefevre, Denis Trystram, Anne-Cécile
Orgerie, and Benjamin Fichel. 2023. An experimental comparison of software-
based power meters: focus on CPU and GPU. 106–118. https://doi.org/10.1109/
CCGrid57682.2023.00020
[26] Alper Kerem. 2022. Investigation of carbon footprint effect of renewable power
plants regarding energy production: A case study of a city in Turkey. Journal of
the Air & Waste Management Association 72, 3 (2022), 294–307.
[27] Jonathan Koomey, Stephen Berard, Marla Sanchez, and Henry Wong. 2011. Im-
plications of Historical Trends in the Electrical Efficiency of Computing. IEEE
Annals of the History of Computing 33, 3 (2011), 46–54. https://doi.org/10.1109/
MAHC.2010.28
[28] Darkwah Williams Kweku, Odum Bismark, Addae Maxwell, Koomson Ato
Desmond, Kwakye Benjamin Danso, Ewurabena Asante Oti-Mensah,
Asenso Theophilus Quachie, and Buanya Beryl Adormaa. 2018. Greenhouse
effect: greenhouse gases and their impact on global warming. Journal of Scientific
research and reports 17, 6 (2018), 1–9.
[29] Loïc Lannelongue, Hans-Erik G. Aronson, Alex Bateman, Ewan Birney, Talia
Caplan, Martin Juckes, Johanna McEntyre, Andrew D. Morris, Gerry Reilly, and
Michael Inouye. 2023. GREENER principles for environmentally sustainable
computational science. Nature Computational Science 3, 6 (June 2023), 514–521.
https://doi.org/10.1038/s43588-023-00461-y
[30] Loïc Lannelongue, Jason Grealey, and Michael Inouye. 2021. Green Al-
gorithms: Quantifying the Carbon Footprint of Computation. Advanced
Science 8, 12 (2021), 2100707. https://doi.org/10.1002/advs.202100707
arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/advs.202100707
[31] Mark Lynas, Benjamin Z Houlton, and Simon Perry. 2021. Greater than 99%
consensus on human caused climate change in the peer-reviewed scientific
literature. Environmental Research Letters 16, 11 (Oct. 2021), 114005. https:
//doi.org/10.1088/1748-9326/ac2966
[32] Haokai Ma, Ruobing Xie, Lei Meng, Xin Chen, Xu Zhang, Leyu Lin, and Jie Zhou. Exploring False Hard Negative Sample in Cross-Domain Recommendation.
In Proceedings of the 17th ACM Conference on Recommender Systems (Singapore,
Singapore) (RecSys ’23). Association for Computing Machinery, New York, NY,
USA, 502–514
[33] Valérie Masson-Delmotte and Intergovernmental Panel on Climate Change. 2022.
Global warming of 1.5°c : An IPCC Special Report on impacts of global warming
of 1.5°c above pre-industrial levels and related global greenhouse gas emission
pathways, in the contex of strengthening the global response to the thereat of blimate
change, sustainable development, and efforts to eradicate poverty. Cambridge
University Press. https://cir.nii.ac.jp/crid/1130574323982454028
[34] Yukta Mehta, Rui Xu, Benjamin Lim, Jane Wu, and Jerry Gao. 2023. A Review for
Green Energy Machine Learning and AI Services. Energies 16, 15 (2023), 5718.
[35] Lien Michiels, Robin Verachtert, and Bart Goethals. 2022. RecPack: An(Other)
Experimentation Toolkit for Top-N Recommendation Using Implicit Feedback
Data. In Proceedings of the 16th ACM Conference on Recommender Systems (Seattle,
WA, USA) (RecSys ’22). Association for Computing Machinery, New York, NY,
USA, 648–651. https://doi.org/10.1145/3523227.3551472
[36] T. Minka, J.M. Winn, J.P. Guiver, Y. Zaykov, D. Fabian, and J. Bronskill. 2018.
/Infer.NET 0.3. Microsoft Research Cambridge. http://dotnet.github.io/infer.
[37] John FB Mitchell. 1989. The “greenhouse” effect and climate change. Reviews of
Geophysics 27, 1 (1989), 115–139.
[38] Ruihui Mu. 2018. A Survey of Recommender Systems Based on Deep Learning.
IEEE Access 6 (2018), 69009–69022. https://doi.org/10.1109/ACCESS.2018.2880197
[39] Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying Recommendations
using Distantly-Labeled Reviews and Fine-Grained Aspects. In Proceedings of
the 2019 Conference on Empirical Methods in Natural Language Processing and
the 9th International Joint Conference on Natural Language Processing (EMNLP-
IJCNLP). Association for Computational Linguistics, Hong Kong, China, 188–197.
https://doi.org/10.18653/v1/D19-1018
[40] Aigul Nukusheva, Gulzhazira Ilyassova, Dinara Rustembekova, Roza Zhamiyeva,
and Leila Arenova. 2021. Global warming problem faced by the international
community: international legal aspect. International Environmental Agreements:
Politics, Law and Economics 21 (2021), 219–233.
[41] Showmick Guha Paul, Arpa Saha, Mohammad Shamsul Arefin, Touhid Bhuiyan,
Al Amin Biswas, Ahmed Wasif Reza, Naif M. Alotaibi, Salem A. Alyami, and
Mohammad Ali Moni. 2023. A Comprehensive Review of Green Computing:
Past, Present, and Future Research. IEEE Access 11 (2023), 87445–87494. https:
//doi.org/10.1109/ACCESS.2023.3304332
[42] Leeya D Pressburger, Meredydd Evans, Sha Yu, Yiyun Cui, Abhishek Somani,
and Gokul C Iyer. 2022. A Comprehensive Economic Coal Transition in South Asia.
Technical Report. Pacific Northwest National Laboratory (PNNL), Richland, WA
(United States).
[43] Katharine Ricke, Laurent Drouet, Ken Caldeira, and Massimo Tavoni. 2018.
Country-level social cost of carbon. Nature Climate Change 8, 10 (Sept. 2018),
895–900. https://doi.org/10.1038/s41558-018-0282-y
[44] Faisal Shehzad and Dietmar Jannach. 2023. Everyone’s a Winner! On Hyper-
parameter Tuning of Recommendation Models. In Proceedings of the 17th ACM
Conference on Recommender Systems (Singapore, Singapore) (RecSys ’23). As-
sociation for Computing Machinery, New York, NY, USA, 652–657. https:
//doi.org/10.1145/3604915.3609488
[45] Rakesh Kumar Sinha and Nitin Dutt Chaturvedi. 2019. A review on carbon
emission reduction in industries and planning emission limits. Renewable and
Sustainable Energy Reviews 114 (2019), 109304.
[46] Giuseppe Spillo, Allegra De Filippo, Cataldo Musto, Michela Milano, and Gio-
vanni Semeraro. 2023. Towards Sustainability-aware Recommender Systems:
Analyzing the Trade-off Between Algorithms Performance and Carbon Footprint.
In Proceedings of the 17th ACM Conference on Recommender Systems (Singapore,
Singapore) (RecSys ’23). Association for Computing Machinery, New York, NY,
USA, 856–862. https://doi.org/10.1145/3604915.3608840
[47] Emma Strubell, Ananya Ganesh, and Andrew McCallum. 2019. Energy and policy
considerations for deep learning in NLP. arXiv preprint arXiv:1906.02243 (2019).
[48] Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang.
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Rep-
resentations from Transformer. In Proceedings of the 28th ACM International
Conference on Information and Knowledge Management (Beijing, China) (CIKM
’19). Association for Computing Machinery, New York, NY, USA, 1441–1450.
https://doi.org/10.1145/3357384.3357895
[49] Aimee Van Wynsberghe. 2021. Sustainable AI: AI for sustainability and the
sustainability of AI. AI and Ethics 1, 3 (2021), 213–218.
[50] Tobias Vente, Michael Ekstrand, and Joeran Beel. 2023. Introducing lenskit-
auto, an experimental automated recommender system (autorecsys) toolkit. In
Proceedings of the 17th ACM Conference on Recommender Systems. 1212–1216.
[51] Chenyang Wang, Min Zhang, Weizhi Ma, Yiqun Liu, and Shaoping Ma. 2020.
Make it a chorus: knowledge-and time-aware item modeling for sequential rec-
ommendation. In Proceedings of the 43rd International ACM SIGIR Conference on
Research and Development in Information Retrieval. 109–118.
[52] Lukas Wegmeth and Joeran Beel. 2022. CaMeLS: Cooperative meta-learning ser-
vice for recommender systems. In Proceedings of the Perspectives on the Evaluation
of Recommender Systems Workshop 2022. CEUR-WS. https://ceur-ws.org/Vol-
3228/paper2.pdf
[53] Lukas Wegmeth, Tobias Vente, Lennart Purucker, and Joeran Beel. 2023. The Effect
of Random Seeds for Data Splitting on Recommendation Accuracy. In Proceeding of the 3rd Workshop Perspectives on the Evaluation of Recommender Systems 2023
co-located with the 17th ACM Conference on Recommender Systems (RecSys 2023),
Singapore, Singapore, September 19, 2023 (CEUR Workshop Proceedings, Vol. 3476),
Alan Said, Eva Zangerle, and Christine Bauer 0001 (Eds.). CEUR-WS.org. https:
//ceur-ws.org/Vol-3476/paper4.pdf
[54] Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia
Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, and Enhong
Chen. 2023. A Survey on Large Language Models for Recommendation.
arXiv:2305.19860 [cs.IR]
[55] Lanling Xu, Zhen Tian, Gaowei Zhang, Junjie Zhang, Lei Wang, Bowen Zheng,
Yifan Li, Jiakai Tang, Zeyu Zhang, Yupeng Hou, Xingyu Pan, Wayne Xin Zhao,
Xu Chen, and Ji-Rong Wen. 2023. Towards a More User-Friendly and Easy-to-Use
Benchmark Library for Recommender Systems. In SIGIR. ACM, 2837–2847.
[56] Zitao Xu, Weike Pan, and Zhong Ming. 2023. A Multi-view Graph Contrastive
Learning Framework for Cross-Domain Sequential Recommendation. In Proceed-
ings of the 17th ACM Conference on Recommender Systems (Singapore, Singapore)
(RecSys ’23). Association for Computing Machinery, New York, NY, USA, 491–501.
https://doi.org/10.1145/3604915.3608785
[57] Kelvin O Yoro and Michael O Daramola. 2020. CO2 emission sources, greenhouse
gases, and the global warming effect. In Advances in carbon capture. Elsevier,
3–28.
[58] Hsiang-Fu Yu, Cho-Jui Hsieh, Si Si, and Inderjit S. Dhillon. 2012. Scalable Coor-
dinate Descent Approaches to Parallel Matrix Factorization for Recommender
Systems. In IEEE International Conference of Data Mining.
[59] Zhenrui Yue, Zhankui He, Huimin Zeng, and Julian McAuley. 2021. Black-
Box Attacks on Sequential Recommenders via Data-Free Model Extraction. In
Proceedings of the 15th ACM Conference on Recommender Systems (Amsterdam,
Netherlands) (RecSys ’21). Association for Computing Machinery, New York, NY,
USA, 44–54. https://doi.org/10.1145/3460231.3474275
[60] Zhenrui Yue, Huimin Zeng, Ziyi Kou, Lanyu Shang, and Dong Wang. 2022.
Defending Substitution-Based Profile Pollution Attacks on Sequential Recom-
menders. In Proceedings of the 16th ACM Conference on Recommender Systems
(Seattle, WA, USA) (RecSys ’22). Association for Computing Machinery, New York,
NY, USA, 59–70.
[61] Shuai Zhang, Lina Yao, Aixin Sun, and Yi Tay. 2019. Deep Learning Based
Recommender System: A Survey and New Perspectives. ACM Comput. Surv. 52,
1, Article 5 (feb 2019), 38 pages. https://doi.org/10.1145/3285029
[62] Jin Zhong, Math Bollen, and Sarah Rönnberg. 2021. Towards a 100% renewable
energy electricity generation system in Sweden. Renewable Energy 171 (2021),
812–824. https://doi.org/10.1016/j.renene.2021.02.153
[63] Kun Zhou, Xiaolei Wang, Yuanhang Zhou, Chenzhan Shang, Yuan Cheng,
Wayne Xin Zhao, Yaliang Li, and Ji-Rong Wen. 2021. CRSLab: An Open-Source
Toolkit for Building Conversational Recommender System. In Proceedings of the
59th Annual Meeting of the Association for Computational Linguistics and the 11th
International Joint Conference on Natural Language Processing: System Demonstra-
tions, Heng Ji, Jong C. Park, and Rui Xia (Eds.). Association for Computational
Linguistics, Online, 185–193. https://doi.org/10.18653/v1/2021.acl-demo.22
[64] You Zhou, Xiujing Lin, Xiang Zhang, Maolin Wang, Gangwei Jiang, Huakang Lu,
Yupeng Wu, Kai Zhang, Zhe Yang, Kehang Wang, Yongduo Sui, Fengwei Jia, Zuoli
Tang, Yao Zhao, Hongxuan Zhang, Tiannuo Yang, Weibo Chen, Yunong Mao,
Yi Li, De Bao, Yu Li, Hongrui Liao, Ting Liu, Jingwen Liu, Jinchi Guo, Xiangyu
Zhao, Ying WEI, Hong Qian, Qi Liu, Xiang Wang, Wai Kin, Chan, Chenliang Li,
Yusen Li, Shiyu Yang, Jining Yan, Chao Mou, Shuai Han, Wuxia Jin, Guannan
Zhang, and Xiaodong Zeng. 2023. On the Opportunities of Green Computing: A
Survey. https://doi.org/10.48550/ARXIV.2311.00447
[65] Jieming Zhu, Quanyu Dai, Liangcai Su, Rong Ma, Jinyang Liu, Guohao Cai, Xi
Xiao, and Rui Zhang. 2022. BARS: Towards Open Benchmarking for Recom-
mender Systems. In SIGIR ’22: The 45th International ACM SIGIR Conference on
Research and Development in Information Retrieval, Madrid, Spain, July 11 – 15,
2022, Enrique Amigó, Pablo Castells, Julio Gonzalo, Ben Carterette, J. Shane
Culpepper, and Gabriella Kazai (Eds.). ACM, 2912–2923. https://doi.org/10.1145/
3477495.3531723
[66] Jiajie Zhu, Yan Wang, Feng Zhu, and Zhu Sun. 2023. Domain Disentanglement
with Interpolative Data Augmentation for Dual-Target Cross-Domain Recom-
mendation. In Proceedings of the 17th ACM Conference on Recommender Systems
(Singapore, Singapore) (RecSys ’23). Association for Computing Machinery, New
York, NY, USA, 515–527.



0 Comments