Our paper “Machine Learning vs. Rules and Out-of-the-Box vs. Retrained: An Evaluation of Open-Source Bibliographic Reference and Citation Parsers” got recently accepted and will be presented at Joint Conference on Digital Libraries 2018.
Abstract: Bibliographic reference parsing refers to extracting machine-readable metadata, such as the names of the authors, the title, or journal name, from bibliographic reference strings. Many approaches to this problem have been proposed so far, including regular expressions, knowledge bases and supervised machine learning. Many open source reference parsers based on various algorithms are also available. In this paper, we apply, evaluate and compare ten reference parsing tools in a specific business use case. The tools are Anystyle-Parser, Biblio, CERMINE, Citation, Citation-Parser, GROBID, ParsCit, PDFSSA4MET, Reference Tagger and Science Parse, and we compare them in both their out-of-the-box versions and versions tuned to the project-specific data. According to our evaluation, the best performing out-of-the-box tool is GROBID (F1 0.89), followed by CERMINE (F1 0.83) and ParsCit (F1 0.75). We also found that even though machine learning-based tools and tools based on rules or regular expressions achieve on average similar precision (0.77 for ML-based tools vs. 0.76 for non-ML-based tools), applying machine learning-based tools results in a recall three times higher than in the case of non-ML-based tools (0.66 vs. 0.22). Our study also confirms that tuning the models to the task-specific data results in the increase in the quality. The retrained versions of reference parsers are in all cases better than their out-of-the-box counterparts; for GROBID F1 increased by 3% (0.92 vs. 0.89), for CERMINE by 11% (0.92 vs. 0.83), and for ParsCit by 16% (0.87 vs. 0.75).
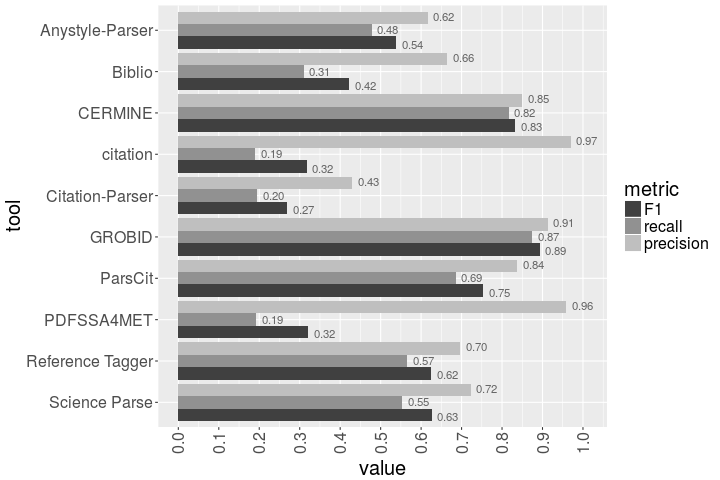
The results of the comparison of 10 open-source bibliographic reference parsers


0 Comments